ĻP(gu©Īn)ė┌ PolarDB PostgreSQL ░µ
PolarDB PostgreSQL ░µ╩Ūę╗┐Ņ░ó└’įŲūįų„čą░l(f©Ī)Ą─įŲįŁ╔·ĻP(gu©Īn)ŽĄą═öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)«a(ch©Żn)ŲĘŻ¼100% ╝µ╚▌ PostgreSQLŻ¼Ė▀Č╚╝µ╚▌OraclešZ(y©│)Ę©;▓╔ė├╗∙ė┌ Shared-Storage Ą─┤µā”(ch©│)ėŗ(j©¼)╦ŃĘųļx╝▄śŗ(g©░u)Ż¼Š▀ėąśOų┬ÅŚąįĪó║┴├ļ╝ē(j©¬)čė▀tĪóHTAP ĪóGanos╚½┐šķgöĄ(sh©┤)ō■(j©┤)╠Ä└Ē─▄┴”║═Ė▀┐╔┐┐ĪóĖ▀┐╔ė├ĪóÅŚąįöU(ku©░)š╣Ą╚Ų¾śI(y©©)╝ē(j©¬)öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)╠žąįĪŻ═¼Ģr(sh©¬)Ż¼PolarDB PostgreSQL ░µŠ▀ėą┤¾ęÄ(gu©®)─Ż▓óąąėŗ(j©¼)╦Ń─▄┴”Ż¼┐╔ęįæ¬(y©®ng)ī”(du©¼) OLTP ┼c OLAP ╗ņ║Žžō(f©┤)▌dĪŻ
PolarDB PostgreSQLĖ▀┐╔ė├╝▄śŗ(g©░u)
é„Įy(t©»ng)ėŗ(j©¼)╦Ń┼c┤µā”(ch©│)Šo±Ņ║ŽĄ─öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)ŽĄĮy(t©»ng)╝▄śŗ(g©░u)├µ┼RųTČÓ╠¶æ(zh©żn)Ż¼╚ńŻ║
1Īó┤µā”(ch©│)┐šķg¤o(w©▓)Ę©│¼▀^(gu©░)å╬ÖC(j©®)╔ŽŽ▐Ż¼▓╗ęūīŹ(sh©¬)¼F(xi©żn)┘Yį┤Ą─┐ņ╦┘öU(ku©░)╚▌;
2Īóę╗┼_(t©ói)╬’└ĒÖC(j©®)Ą─▓╗═¼┘Yį┤ļyęį═¼Ģr(sh©¬)Š▀ėą▌^Ė▀Ą─└¹ė├┬╩Ż¼┘Yį┤ęū╦ķŲ¼╗»;
3Īóå╬ę╗┘Yį┤╣╩šŽĢ■(hu©¼)ī¦(d©Żo)ų┬ŽĄĮy(t©»ng)š¹¾w╣╩šŽŻ¼ŽĄĮy(t©»ng)╗ųÅ═(f©┤)Ģr(sh©¬)ķgķL(zh©Żng)ĪŻ
PolarDB PostgreSQL▓╔ė├ėŗ(j©¼)╦Ń┼c┤µā”(ch©│)ĘųļxĄ─╝▄śŗ(g©░u)Ż¼ŽÓ▒╚ė┌Šo±Ņ║Ž╝▄śŗ(g©░u)Ż¼┤µā”(ch©│)┘Yį┤▒╗å╬¬Ü(d©▓)ĮŌ±ŅĮM│╔ę╗éĆ(g©©)¬Ü(d©▓)┴óĄ─┤µā”(ch©│)│žŻ¼┐╔¬Ü(d©▓)┴ó╠ßĖ▀┤µā”(ch©│)│žĄ─┘Yį┤└¹ė├┬╩;═¼Ģr(sh©¬)ų„╣Ø(ji©”)³c(di©Żn)┼cČÓéĆ(g©©)ų╗ūx╣Ø(ji©”)³c(di©Żn)┐╔╣▓ŽĒ═¼ę╗Ę▌┤µā”(ch©│)Ż¼╣Ø(ji©”)╝s┴╦ų╗ūx╣Ø(ji©”)³c(di©Żn)Ą─┤µā”(ch©│)ķ_(k©Īi)õN(xi©Īo)Ż¼▀M(j©¼n)ę╗▓ĮĮĄĄ═┴╦┤µā”(ch©│)│╔▒Š;ėŗ(j©¼)╦Ń┤µā”(ch©│)ĘųļxĄ─įO(sh©©)ėŗ(j©¼)╩╣Ą├ėŗ(j©¼)╦Ń╝»╚║┼c┤µā”(ch©│)╝»╚║Š∙┐╔¬Ü(d©▓)┴óöU(ku©░)š╣Ż¼śO┤¾Ąž╠ßĖ▀┴╦┘Yį┤ÅŚąį;┤╦═Ō╣Ø(ji©”)³c(di©Żn)ķg═©▀^(gu©░)╚šųŠą┼ŽóüĒ(l©ói)═¼▓Įā╚(n©©i)┤µĀŅæB(t©żi)Ż¼▓╗Ģ■(hu©¼)«a(ch©Żn)╔·IOŻ¼┤¾┤¾ĮĄĄ═╣Ø(ji©”)³c(di©Żn)═¼▓Įčė▀tŻ¼×ķśOų┬Ė▀┐╔ė├╠ß╣®┴╦╗∙ĄA(ch©│)ĪŻ
į┌ėŗ(j©¼)╦Ń┤µā”(ch©│)ĘųļxĄ─╝▄śŗ(g©░u)Ž┬Ż¼PolarDB PostgreSQL┐╔═¼Ģr(sh©¬)╠ß╣®AZā╚(n©©i)/┐ńAZ/┐ńė“╝ē(j©¬)äeĄ─Ė▀┐╔ė├ĪŻ▀@└’░čę╗éĆ(g©©)PolarDBöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)ėŗ(j©¼)╦Ń┼c┤µā”(ch©│)╣Ø(ji©”)³c(di©Żn)Ż¼ęį╝░Ė▀┐╔ė├┐žųŲ─ŻēKĪó▀\(y©┤n)ŠS╣▄└Ē─ŻēKŻ¼Įy(t©»ng)ĘQ(ch©źng)×ķę╗éĆ(g©©)PolarDB╝»╚║ĪŻÅ─öĄ(sh©┤)ō■(j©┤)īė├µüĒ(l©ói)┐┤Ż¼PolarDBĄ─Ė▀┐╔ė├╝▄śŗ(g©░u)╚ńŽ┬Ż║
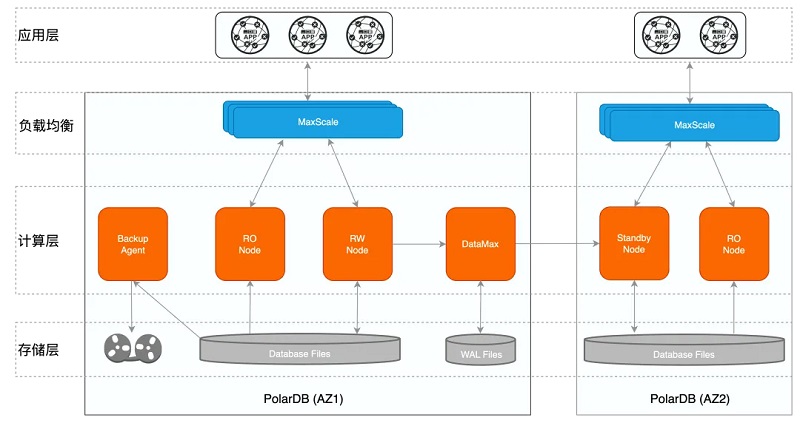
å╬╠ūPolarDB╝»╚║▓┐╩į┌ę╗éĆ(g©©)┐╔ė├ģ^(q©▒)ā╚(n©©i)Ż¼▓╗═¼Ą─PolarDB╝»╚║ų«ķg╗ź×ķ×─(z©Īi)éõŻ¼ų„éõ─Ż╩Į▒ŻūC┐ńAZ/┐ńė“╝ē(j©¬)äeĄ─Ė▀┐╔ė├;
1ĪóPolarDB╝»╚║×ķę╗īæ(xi©¦)ČÓūx╝▄śŗ(g©░u)Ż¼ūxīæ(xi©¦)╣Ø(ji©”)³c(di©Żn)╣▓ŽĒ═¼ę╗Ę▌┤µā”(ch©│)Ż¼ėąą¦ĮĄĄ═┤µā”(ch©│)│╔▒ŠŻ¼═¼Ģr(sh©¬)ų╗ūx╣Ø(ji©”)³c(di©Żn)▀Ć┐╔īŹ(sh©¬)¼F(xi©żn)å╬éĆ(g©©)AZā╚(n©©i)ėŗ(j©¼)╦Ń╣Ø(ji©”)³c(di©Żn)Ą─Ė▀┐╔ė├;
2ĪóDataMax╣Ø(ji©”)³c(di©Żn)ų╗▒Ż┤µWAL╚šųŠ╬─╝■Ż¼▓╗┼cīæ(xi©¦)╣Ø(ji©”)³c(di©Żn)╣▓ŽĒöĄ(sh©┤)ō■(j©┤)Ż¼į┌╠ß╣®▀h(yu©Żn)│╠═¼▓Į╣”─▄Ą─═¼Ģr(sh©¬)Ż¼┐╔ęįĖ³Ė▀ą¦ĄžīŹ(sh©¬)¼F(xi©żn)┐ńė“╝ē(j©¬)äeĄ─Ė▀┐╔ė├;
3ĪóBackupAgent═©▀^(gu©░)š{(di©żo)ė├Ęų▓╝╩Į╬─╝■ŽĄĮy(t©»ng)Ą─Įė┐┌▀M(j©¼n)ąą┐ņ╦┘öĄ(sh©┤)ō■(j©┤)éõĘ▌Ż¼éõĘ▌ų¦│ų▒ŠĄž▒P(p©ón)ĪóOSSĪóDBSĄ╚Ż¼▒ŻūC╣╩šŽ░l(f©Ī)╔·Ģr(sh©¬)┐╔╗∙ė┌éõĘ▌▀M(j©¼n)ąąöĄ(sh©┤)ō■(j©┤)Ą─╗ųÅ═(f©┤)Ż¼Ę└ų╣öĄ(sh©┤)ō■(j©┤)üG╩¦/ōpē─;
4ĪóMaxScale╩Ū┤·└ĒīėŻ¼┐╔ūįäė(d©░ng)ūR(sh©¬)äeūxīæ(xi©¦)šł(q©½ng)Ū¾Ż¼Ė∙ō■(j©┤)ų╗ūxžō(f©┤)▌dīóūxšł(q©½ng)Ū¾░l(f©Ī)╦═Įo▓╗═¼Ą─ų╗ūx╣Ø(ji©”)³c(di©Żn)Ż¼═©▀^(gu©░)ūxīæ(xi©¦)ĘųļxīŹ(sh©¬)¼F(xi©żn)žō(f©┤)▌dŠ∙║ŌĪŻ
į┌ę╗éĆ(g©©)┐╔ė├ģ^(q©▒)ā╚(n©©i)Ż¼PolarDBĄ─RWĪóRO╣Ø(ji©”)³c(di©Żn)ķg▒Ż│ųĮėĮ³ė┌īŹ(sh©¬)Ģr(sh©¬)Ą─ā╚(n©©i)┤µ═¼▓ĮŻ¼╚ń╣¹RW│÷¼F(xi©żn)╣╩šŽŻ¼┐╔ęįļSĢr(sh©¬)▀M(j©¼n)ąąRW/RO╣Ø(ji©”)³c(di©Żn)ŪąōQŻ¼īŹ(sh©¬)¼F(xi©żn)å╬éĆ(g©©)AZā╚(n©©i)Ą─Ė▀┐╔ė├;į┌╝»╚║ķgŻ¼ā╔éĆ(g©©)╝»╚║═©▀^(gu©░)╚šųŠ▀M(j©¼n)ąą╬’└ĒÅ═(f©┤)ųŲŻ¼ųąķgėąę╗éĆ(g©©)DataMax╚šųŠųą└^╣Ø(ji©”)³c(di©Żn)Ż¼ų„╝»╚║┼cDataMaxķg┼õų├×ķ═¼▓Į─Ż╩ĮŻ¼▀h(yu©Żn)│╠╝»╚║┼õų├×ķ«É▓ĮÅ═(f©┤)ųŲŻ¼Å─Č°į┌ąį─▄ĘĆ(w©¦n)Č©Ą─ŪķørŽ┬Ż¼▒ŻšŽ┐ńAZ/┐ńė“Ė▀┐╔ė├Ą─RPO=0ĪŻ┤╦═ŌŻ¼╚ń╣¹ė├æ¶(h©┤)ėą3éĆ(g©©)┐╔ė├ģ^(q©▒)Ż¼▀Ć┐╔ęį▓┐╩×ķPaxos╚²╣Ø(ji©”)³c(di©Żn)─Ż╩ĮŻ¼Ųõųąę╗éĆ(g©©)╣Ø(ji©”)³c(di©Żn)ų╗▒Ż┤µ╚šųŠŻ¼Å─Č°īŹ(sh©¬)¼F(xi©żn)Ą═│╔▒Š│¼Ė▀┐╔ė├ąį─▄┴”ĪŻ
Å─┐žųŲīė├µüĒ(l©ói)┐┤Ż¼PolarDBĄ─Ė▀┐╔ė├╝▄śŗ(g©░u)╚ńŽ┬Ż║
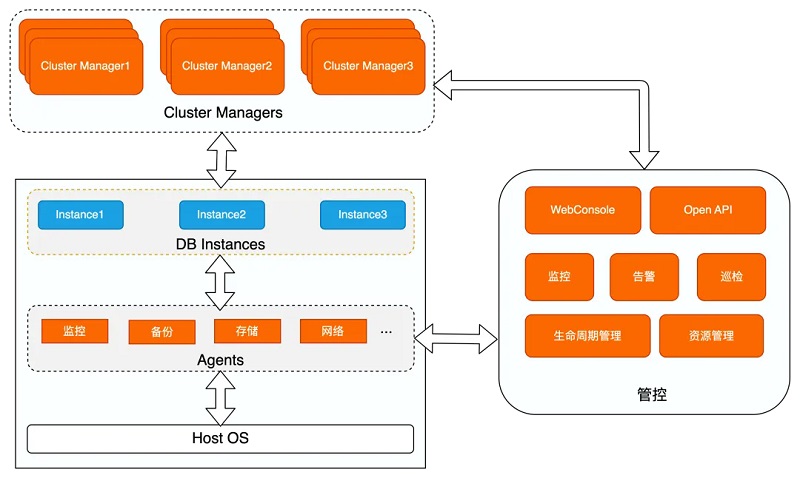
ŲõųąŻ║
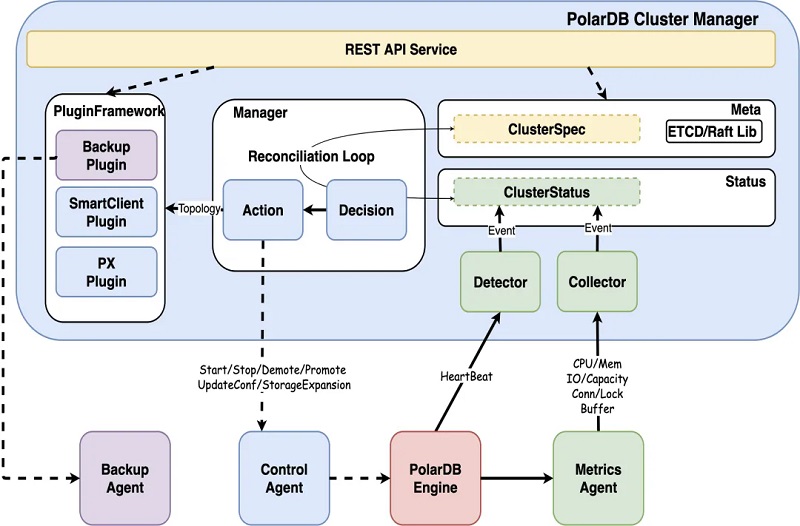
1ĪóCluster Manager×ķ╝»╚║╣▄└Ēųąą─Ż¼═©▀^(gu©░)ą─╠°öĄ(sh©┤)ō■(j©┤)▒O(ji©Īn)┐ž?c©ói)?sh©┤)ō■(j©┤)Äņ(k©┤)īŹ(sh©¬)└²ĪóMaxScale╝░AgentĄ─┐╔ė├ąįŻ¼═©▀^(gu©░)ŪąōQ╗“ųžåó«É│Ż╣Ø(ji©”)³c(di©Żn)üĒ(l©ói)ŠSūo(h©┤)╝»╚║Ą─Ė▀┐╔ė├Ż¼╠ß╣®ų„äė(d©░ng)▒O(ji©Īn)┐ž║═┐ņ╦┘Öz£y(c©©)╣╩šŽĄ──▄┴”;
2Īó▀\(y©┤n)ąąį┌ų„ÖC(j©®)╔ŽĄ─▓╗═¼Agentžō(f©┤)ž¤(z©”)▒O(ji©Īn)┐žĪó▓╔╝»╗“┼õų├öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)īŹ(sh©¬)└²║═ų„ÖC(j©®)Ą─ą┼ŽóŻ¼▓ó╔·│╔ī”(du©¼)æ¬(y©®ng)Ą─▒O(ji©Īn)┐žęĢłDŻ¼═¼Ģr(sh©¬)▓┐ĘųųĖś╦(bi©Īo)ę▓▌ö│÷ų┴Cluster Managerųą▌oų·øQ▓▀;
3Īó╣▄┐žžō(f©┤)ž¤(z©”)┘Yį┤╣▄└Ē╝░öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)īŹ(sh©¬)└²╔·├³ų▄Ų┌╣▄└ĒŻ¼Ųõ╗∙ė┌Agent▓╔╝»Ą─ą┼Žó▀M(j©¼n)ąą▒O(ji©Īn)┐ž╝░ĖµŠ»Ż¼▒Ńė┌Ė³┐ņ╦┘╝░Ģr(sh©¬)ĄžĒææ¬(y©®ng)▓ó╠Ä└Ē╣╩šŽŻ¼═¼Ģr(sh©¬)╠ß╣®webČ╦╣®ė├æ¶(h©┤)▓ķįā(x©▓n)╝░ą▐Ė─Ż¼╠ß╣®Open APIĮė┐┌ĮoĄ┌╚²ĘĮŲĮ┼_(t©ói)š{(di©żo)ė├Ż¼╩╣Ą├öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Ą─╣▄└ĒĖ³╝ė▒ŃĮ▌ĪŻ
PolarDBė├æ¶(h©┤)┐╔ęįĖ∙ō■(j©┤)ūį╝║Ą─īŹ(sh©¬)ļHŪķør║═SLAę¬Ū¾Ż¼į┌å╬┐╔ė├ģ^(q©▒)Īóļp┐╔ė├ģ^(q©▒)Īó╚²┐╔ė├ģ^(q©▒)Īó┐ńė“Ą╚ČÓĘNŁh(hu©ón)Š│Ž┬Ż¼ņ`╗ŅĄ─▀xō±┐╔ė├ąįĘĮ░ĖĪŻŽ┬├µĘųäeī”(du©¼)å╬┐╔ė├ģ^(q©▒)ā╚(n©©i)ėŗ(j©¼)╦Ń╣Ø(ji©”)³c(di©Żn)Ą─Ė▀┐╔ė├Īóļp┐╔ė├ģ^(q©▒)/┐ńė“ķgėŗ(j©¼)╦Ń╝»╚║Ą─Ė▀┐╔ė├Īó╚²┐╔ė├ģ^(q©▒)DMAĖ▀┐╔ė├ĘĮ░ĖĄ─║╦ą─╝╝ąg(sh©┤)╝░įŁ└Ē▀M(j©¼n)ąąįö╝Ü(x©¼)ĮķĮBĪŻ
ėŗ(j©¼)╦Ń╣Ø(ji©”)³c(di©Żn)Ė▀┐╔ė├
PolarDBå╬éĆ(g©©)AZā╚(n©©i)ėŗ(j©¼)╦Ń╣Ø(ji©”)³c(di©Żn)Ą─Ė▀┐╔ė├═©▀^(gu©░)ų╗ūx╣Ø(ji©”)³c(di©Żn)ROīŹ(sh©¬)¼F(xi©żn)Ż¼ūxīæ(xi©¦)╣Ø(ji©”)³c(di©Żn)RW┼cų╗ūx╣Ø(ji©”)³c(di©Żn)RO╣▓ŽĒĄūīė┤µā”(ch©│)öĄ(sh©┤)ō■(j©┤)Ż¼RW┬õ▒P(p©ón)Ą─öĄ(sh©┤)ō■(j©┤)RO┐╔ų▒Įėūx╚ĪĪŻę“┤╦«ö(d©Īng)ūxīæ(xi©¦)╣Ø(ji©”)³c(di©Żn)RW«É│ŻcrashĢr(sh©¬)Ż¼┐╔═©▀^(gu©░)īóRO╣Ø(ji©”)³c(di©Żn)╠ß╔²×ķRW╣Ø(ji©”)³c(di©Żn)üĒ(l©ói)īŹ(sh©¬)¼F(xi©żn)ėŗ(j©¼)╦Ń╣Ø(ji©”)³c(di©Żn)Ą─Ė▀┐╔ė├ĪŻė╔ė┌RW╣Ø(ji©”)³c(di©Żn)┼cRO╣Ø(ji©”)³c(di©Żn)╣▓ŽĒ┤µā”(ch©│)Ż¼ę“┤╦┐╔▒ŻūCRPO=0ĪŻ×ķ▒ŻūCæ¬(y©®ng)ė├īėĘ■äš(w©┤)╦∙ęŖ(ji©żn)öĄ(sh©┤)ō■(j©┤)Ą─ę╗ų┬ąįŻ¼RO╣Ø(ji©”)³c(di©Żn)╠ß╔²×ķRW╣Ø(ji©”)³c(di©Żn)ų«║¾Ż¼ąĶ╗žĘ┼═Ļ┤µā”(ch©│)╔ŽĄ─╦∙ėąWAL╚šųŠöĄ(sh©┤)ō■(j©┤)▓┼┐╔ī”(du©¼)═Ō╠ß╣®Ę■äš(w©┤)Ż¼ę“┤╦RO┼cRWų«ķgĄ─čė▀tī”(du©¼)ė┌RTOų┴ĻP(gu©Īn)ųžę¬Ż¼Č°ŪęįĮąĪįĮ║├ĪŻ╣Ø(ji©”)³c(di©Żn)ķg╩Ū═©▀^(gu©░)é„▌ö╚šųŠą┼Žó▀M(j©¼n)ąą═¼▓ĮĄ─ĪŻūóęŌ▀@└’ų╗é„▌ö╚šųŠĄ─Metadataą┼ŽóŻ¼▀@ą®╚šųŠĘŪ│Ż╚▌ęūĮŌ╬÷Ż¼▀@śėū÷┐╔ęįūīROęįĮėĮ³ė┌īŹ(sh©¬)Ģr(sh©¬)Ą─čė▀tĮė╩šĪóĮŌ╬÷▀@ą®MetadataĪŻĮė╩š▀@ą®ą┼Žó║¾Ż¼RO▓ķšęūį╝║Ą─BufferpoolŻ¼╚ń╣¹Bufferpoolėąī”(du©¼)æ¬(y©®ng)Ą─Ēō(y©©)├µŻ¼ätī”(du©¼)▀@ą®Ēō(y©©)├µ▀M(j©¼n)ąą╩¦ą¦▓┘ū„ĪŻ«ö(d©Īng)RO╔Žėą▓ķįā(x©▓n)ūx╚ĪĄĮ▀@ą®╩¦ą¦Ēō(y©©)├µŻ¼ätī”(du©¼)▀@ą®╩¦ą¦Ēō(y©©)├µå╬¬Ü(d©▓)▓ķšę║═æ¬(y©®ng)ė├Ųõī”(du©¼)æ¬(y©®ng)Ą─╚šųŠŻ¼╩╣Ųõųžą┬ūā?y©Łu)ķėąą¦Ą─ą┬░µ▒ŠĒ?y©©)├µĪŻ▀@ĘN╝╝ąg(sh©┤)ėą╚ńŽ┬ā×(y©Łu)ä▌(sh©¼)Ż║
1Īó┴„Å═(f©┤)ųŲų╗é„▌öWAL MetadataöĄ(sh©┤)ō■(j©┤)Ż¼ĮĄĄ═ŠW(w©Żng)Įj(lu©░)é„▌ö┴┐║═ĮŌ╬÷Ģr(sh©¬)Ą─CPUŽ¹║─;
2Īó╚šųŠ═¼▓ĮĢr(sh©¬)Ż¼ų╗ī”(du©¼)ā╚(n©©i)┤µĒō(y©©)├µū÷╩¦ą¦▓┘ū„Ż¼¤o(w©▓)ąĶūx╚Ī║═æ¬(y©®ng)ė├╚šųŠŻ¼▓╗Ģ■(hu©¼)ėąIO▓┘ū„ĪŻ
▀@śėŻ¼ROė├ūŅ╔┘Ą─öĄ(sh©┤)ō■(j©┤)┴┐║═▓Į¾E═Ļ│╔┴╦═¼▓ĮŻ¼īŹ(sh©¬)¼F(xi©żn)┴╦śOų┬Ą─(═©│ŻĄ═ė┌1ms)Ą─RO┼cRW╣Ø(ji©”)³c(di©Żn)čė▀tŻ¼┤_▒Ż┴╦ROę╗ų┬ąį║═┐╔ė├ąįĪŻŽ┬├µįö╝Ü(x©¼)ĮķĮB▀@éĆ(g©©)═¼▓Į▀^(gu©░)│╠ĪŻ
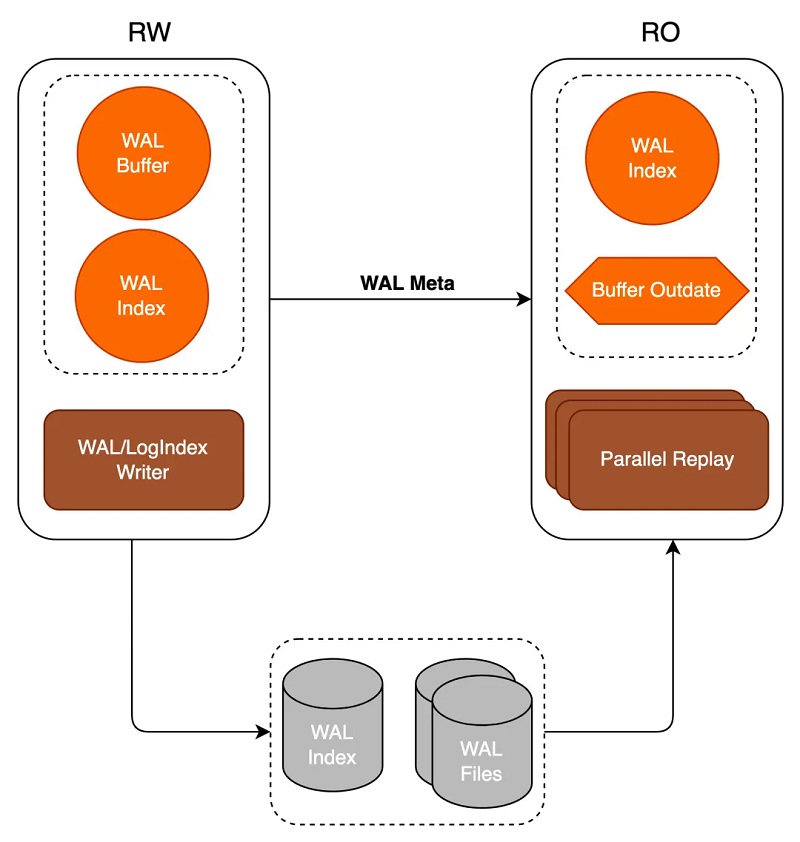
╣Ø(ji©”)³c(di©Żn)ķg═¼▓ĮįŁ└Ē
Ž╚┐┤Ž┬é„Įy(t©»ng)ų„éõ─Ż╩ĮŽ┬Ż¼┴„Å═(f©┤)ųŲé„▌ö┼céõÄņ(k©┤)╗žĘ┼╚šųŠĄ─▀^(gu©░)│╠Ż║
1Īó«ö(d©Īng)RW╣Ø(ji©”)³c(di©Żn)ųąĄ─╩┬äš(w©┤)ī”(du©¼)ŲõöĄ(sh©┤)ō■(j©┤)▀M(j©¼n)ąąą▐Ė─Ģr(sh©¬)Ż¼Ģ■(hu©¼)╔·│╔ī”(du©¼)æ¬(y©®ng)Ą─WAL╚šųŠ▓óīóŲõīæ(xi©¦)╚ļwalbuffer;
2Īó═¼▓Į┴„Å═(f©┤)ųŲ─Ż╩ĮŽ┬Ż¼╩┬äš(w©┤)╠ßĮ╗Ģr(sh©¬)Ģ■(hu©¼)Ž╚īówalbufferųąī”(du©¼)æ¬(y©®ng)Ą─WAL╚šųŠflushĄĮ┤┼▒P(p©ón)Ż¼┤╦║¾Ģ■(hu©¼)åŠąčWalSender▀M(j©¼n)│╠;
3ĪóWalSender▀M(j©¼n)│╠░l(f©Ī)¼F(xi©żn)ėąą┬Ą─╚šųŠ┐╔ęį░l(f©Ī)╦═Ż¼ätÅ─┤┼▒P(p©ón)ųąūx╚Īī”(du©¼)æ¬(y©®ng)Ą─╚šųŠöĄ(sh©┤)ō■(j©┤)Ż¼═©▀^(gu©░)ęčĮ©┴óĄ─┴„Å═(f©┤)ųŲ▀BĮė░l(f©Ī)╦═ĄĮī”(du©¼)Č╦Ą─Standby;
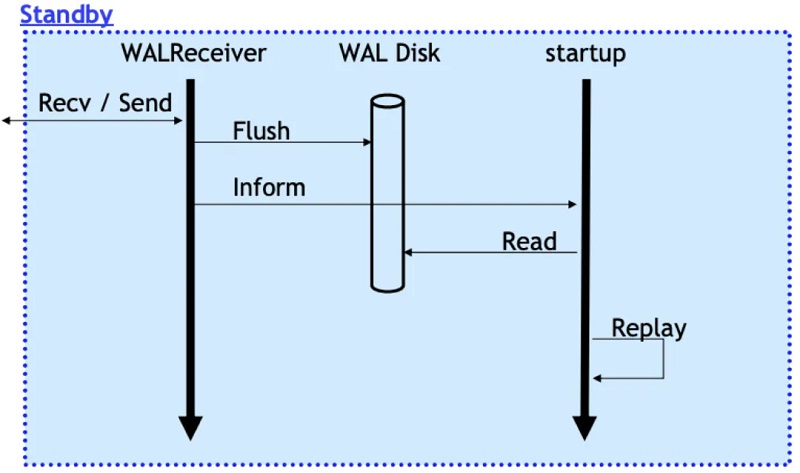
4ĪóStandbyĄ─WalReceiver▀M(j©¼n)│╠Įė╩šĄĮą┬Ą─╚šųŠöĄ(sh©┤)ō■(j©┤)ų«║¾Ż¼═¼śėĄžīóŲõflushĄĮī”(du©¼)æ¬(y©®ng)Ą─┤┼▒P(p©ón)╚šųŠ╬─╝■ųąŻ¼═¼Ģr(sh©¬)═©ų¬Startup▀M(j©¼n)│╠ėąą┬Ą─╚šųŠĄĮ▀_(d©ó);
5ĪóStartupÅ─┤┼▒P(p©ón)╬─╝■ųąūx╚Īī”(du©¼)æ¬(y©®ng)Ą─XLOG Record▀M(j©¼n)ąą╗žĘ┼ĪŻ
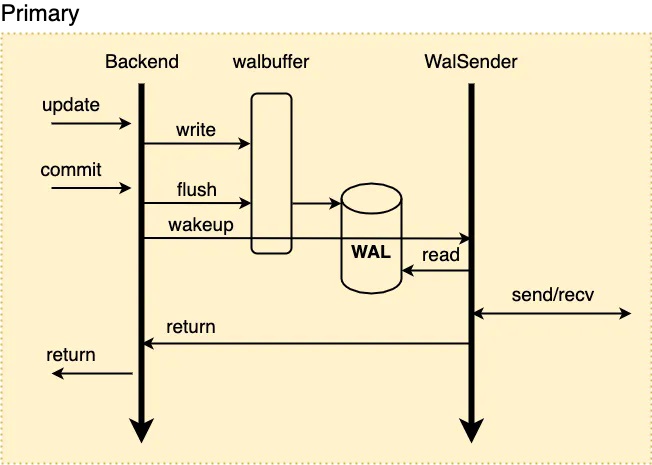
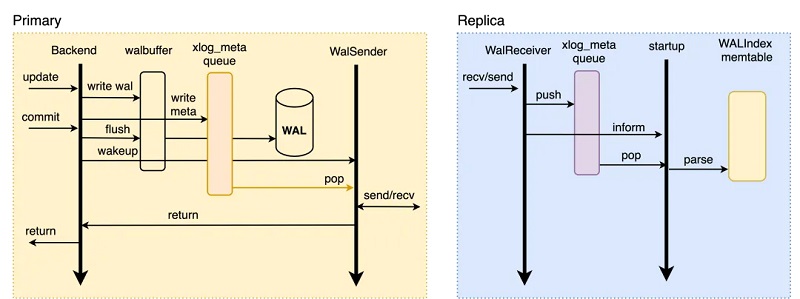
į┌PolarDB▀@ĘN╣▓ŽĒ┤µā”(ch©│)─Ż╩ĮŽ┬Ż¼RW┼cRO╣▓ŽĒĄūīė┤µā”(ch©│)öĄ(sh©┤)ō■(j©┤)Ż¼ę“┤╦RW¤o(w©▓)ąĶé„▌öWAL╚šųŠĄ─╚½▓┐?j©®)?n©©i)╚▌ų┴ROŻ¼ų╗ąĶé„▌öWAL╚šųŠį¬ą┼ŽóMETAŻ¼RO┐╔╗∙ė┌METAų▒ĮėÅ─Ąūīė┤µā”(ch©│)╔Žūx╚Ī╦∙ąĶꬥ─WAL╚šųŠöĄ(sh©┤)ō■(j©┤)Ż¼╚ńŽ┬╦∙╩ŠŻ║
1Īó«ö(d©Īng)RW╣Ø(ji©”)³c(di©Żn)ųąĄ─╩┬äš(w©┤)ī”(du©¼)ŲõöĄ(sh©┤)ō■(j©┤)▀M(j©¼n)ąąą▐Ė─Ģr(sh©¬)Ż¼Ģ■(hu©¼)╔·│╔ī”(du©¼)æ¬(y©®ng)Ą─WAL╚šųŠ▓óīóŲõīæ(xi©¦)╚ļwalbufferŻ¼═¼Ģr(sh©¬)┐ĮžÉī”(du©¼)æ¬(y©®ng)Ą─WAL metaöĄ(sh©┤)ō■(j©┤)ų┴ā╚(n©©i)┤µųąĄ─meta queueųą;
2Īó═¼▓Į┴„Å═(f©┤)ųŲ─Ż╩ĮŽ┬Ż¼╩┬äš(w©┤)╠ßĮ╗Ģr(sh©¬)Ģ■(hu©¼)Ž╚īówalbufferųąī”(du©¼)æ¬(y©®ng)Ą─WAL╚šųŠflushĄĮ┤┼▒P(p©ón)Ż¼┤╦║¾Ģ■(hu©¼)åŠąčWalSender▀M(j©¼n)│╠;
3ĪóWalSender▀M(j©¼n)│╠░l(f©Ī)¼F(xi©żn)ėąą┬Ą─╚šųŠ┐╔ęį░l(f©Ī)╦═Ż¼ätÅ─meta queueųąūx╚Īī”(du©¼)æ¬(y©®ng)Ą─WAL metaŻ¼═©▀^(gu©░)ęčĮ©┴óĄ─┴„Å═(f©┤)ųŲ▀BĮė░l(f©Ī)╦═ĄĮī”(du©¼)Č╦Ą─RO;
4ĪóROĄ─WalReceiver▀M(j©¼n)│╠Įė╩šĄĮą┬Ą─╚šųŠöĄ(sh©┤)ō■(j©┤)ų«║¾Ż¼īóŲõpushĄĮā╚(n©©i)┤µĄ─meta queueųąŻ¼═¼Ģr(sh©¬)═©ų¬Startup▀M(j©¼n)│╠ėąą┬Ą─╚šųŠĄĮ▀_(d©ó);
5ĪóStartupÅ─meta queueųąūx╚Īī”(du©¼)æ¬(y©®ng)Ą─metaöĄ(sh©┤)ō■(j©┤)Ż¼ĮŌ╬÷╔·│╔ī”(du©¼)æ¬(y©®ng)Ą─WAL Index memtable╝┤┐╔ĪŻ
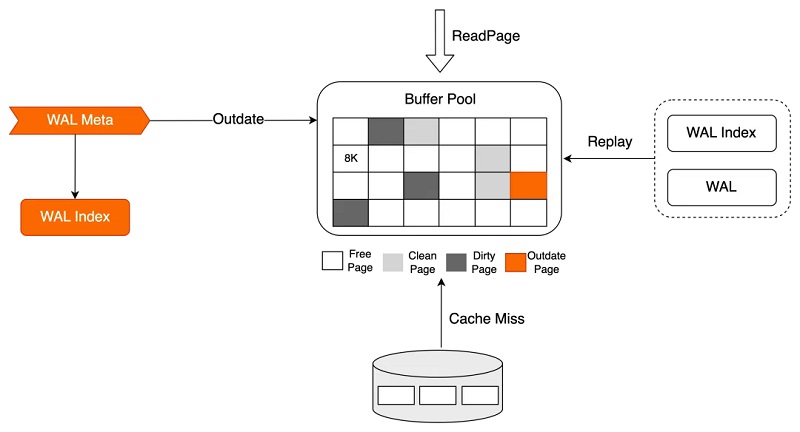
ROĄ─Startup▓ó▓╗īŹ(sh©¬)┘|(zh©¼)ūx╚ĪWAL╚šųŠ▓ó▀M(j©¼n)ąąöĄ(sh©┤)ō■(j©┤)╗žĘ┼▓┘ū„Ż¼öĄ(sh©┤)ō■(j©┤)Ą─╗žĘ┼▒╗čė║¾ĄĮšµš²ėąė├æ¶(h©┤)▀M(j©¼n)│╠įLå¢(w©©n)įōpageĢr(sh©¬)▀M(j©¼n)ąąŻ║
1ĪóStartup╗žĘ┼▀M(j©¼n)│╠į┌Įė╩šĄĮWAL metaöĄ(sh©┤)ō■(j©┤)║¾āHį┌ā╚(n©©i)┤µųą╔·│╔ī”(du©¼)æ¬(y©®ng)Ą─WAL IndexŻ¼═¼Ģr(sh©¬)╚¶įōWAL metaī”(du©¼)æ¬(y©®ng)Ą─page┤µį┌ė┌Buffer PoolųąŻ¼ätīóŲõś╦(bi©Īo)ėø×ķOutdate;
2ĪóĢ■(hu©¼)įÆ▀M(j©¼n)│╠▀M(j©¼n)ąąöĄ(sh©┤)ō■(j©┤)įLå¢(w©©n)Ģr(sh©¬)Ż¼╚¶įōī”(du©¼)æ¬(y©®ng)Ą─page▓╗į┌Buffer PoolųąŻ¼╗“į┌Buffer Poolųą▒╗ś╦(bi©Īo)ėø×ķOutdateŻ¼ät╗∙ė┌WAL IndexÖz╦„ī┘ė┌įōĒō(y©©)├µĄ─ąĶę¬╗žĘ┼Ą─WAL╚šųŠŻ¼▓óÅ─┤┼▒P(p©ón)╔Žūx╚Īī”(du©¼)æ¬(y©®ng)Ą─WAL╚šųŠöĄ(sh©┤)ō■(j©┤)▀M(j©¼n)ąąšµš²Ą─╗žĘ┼▓┘ū„Ż¼╗žĘ┼═Ļ│╔║¾Ž“Ģ■(hu©¼)įÆ▀M(j©¼n)│╠ĘĄ╗žī”(du©¼)æ¬(y©®ng)öĄ(sh©┤)ō■(j©┤)ĪŻ
═©▀^(gu©░)£p╔┘┴„Å═(f©┤)ųŲ▀^(gu©░)│╠ųąūx╚Ī/Įė╩šWALę²╚ļĄ─┤┼▒P(p©ón)IO▓┘ū„Ż¼═¼Ģr(sh©¬)£p╔┘ŠW(w©Żng)Įj(lu©░)é„▌ö┴┐Ż¼ęį╝░ī󚵚²Ą─╗žĘ┼▀^(gu©░)│╠▐D(zhu©Żn)ęŲĄĮĢ■(hu©¼)įÆ▀M(j©¼n)│╠ųąĄ╚ā×(y©Łu)╗»Ż¼╝ė╦┘┴╦RO╣Ø(ji©”)³c(di©Żn)Ą─ā╚(n©©i)┤µ═¼▓Į▀M(j©¼n)│╠Ż¼īóRW┼cROų«ķgĄ─čė▀tĮĄų┴┴╦ūŅĄ═(═©│Ż1msęį?x©▓n)?n©©i))Ż¼Å─Č°╠ß╔²┴╦ROĄ─┐╔ė├ąįĪŻ
Online Promote
į┌╣▓ŽĒ┤µā”(ch©│)╝▄śŗ(g©░u)Ž┬Ż¼ūŅ║å(ji©Żn)å╬Ą─╣Ø(ji©”)³c(di©Żn)ŪąōQĘĮ╩ĮŻ¼╩Ū╗∙ė┌ųžåóĄ─ĘĮ╩Į▀M(j©¼n)ąąHAŪąōQĪŻį┌▀@ĘNĘĮ╩ĮųąŻ¼RW«É│Żcrashų«║¾Ż¼RO╣Ø(ji©”)³c(di©Żn)ęįRW╔ĒĘ▌ųžåóŻ¼┤╦Ģr(sh©¬)ą┬Ą─RWąĶę¬Å─checkpoint³c(di©Żn)ķ_(k©Īi)╩╝╗žĘ┼═Ļ╦∙ėą╚šųŠų«║¾▓┼┐╔ī”(du©¼)═Ō╠ß╣®Ę■äš(w©┤)Ż¼«ö(d©Īng)checkpoint┬õ║¾▌^ČÓĢr(sh©¬)Ż¼ą┬Ą─RWåóäė(d©░ng)▀^(gu©░)│╠ųąąĶę¬╗žĘ┼▌^ČÓĄ─╚šųŠöĄ(sh©┤)ō■(j©┤)Ż¼ī¦(d©Żo)ų┬«É│Żcrash║¾Ę■äš(w©┤)╗ųÅ═(f©┤)Ģr(sh©¬)ķgķL(zh©Żng)ĪŻ
×ķ┴╦▒▄├ŌųžåóĘĮ╩ĮĄ─å¢(w©©n)Ņ}Ż¼PolarDB╩╣ė├Online PromoteĄ─ĘĮ╩ĮīóRO╠ß╔²×ķRWŻ¼įō▀^(gu©░)│╠¤o(w©▓)ąĶųžåóRO╣Ø(ji©”)³c(di©Żn)Ż║

į┌Online Promote▀^(gu©░)│╠ųąŻ¼Promote║¾ROÅ─ŪąōQŪ░Ą─Replay╗žĘ┼╬╗³c(di©Żn)└^└m(x©┤)╗žĘ┼└ŽĄ─RW╔·│╔Ą─╚šųŠĪŻ═¼śėĄ─Ż¼RO╣Ø(ji©”)³c(di©Żn)Ą─╗žĘ┼▀^(gu©░)│╠āH╔·│╔ī”(du©¼)æ¬(y©®ng)Ą─WAL IndexöĄ(sh©┤)ō■(j©┤)Ż¼WAL Index╔·│╔═Ļ«ģų«║¾╝┤┐╔╗ųÅ═(f©┤)Ę■äš(w©┤)Ż¼Ģ■(hu©¼)įÆ▀M(j©¼n)│╠įLå¢(w©©n)PageĢr(sh©¬)Ż¼╗∙ė┌WAL Index╗žĘ┼įōP(y©óng)ageī”(du©¼)æ¬(y©®ng)Ą─WAL╚šųŠŻ¼ROąĶę¬╗žĘ┼Ą─╚šųŠöĄ(sh©┤)┴┐▓ó▓╗╩▄checkpointė░ĒæŻ¼═©▀^(gu©░)Online Promote£p╔┘ROąĶę¬╗žĘ┼Ą─╚šųŠ┴┐Ż¼┐sČ╠╗žĘ┼Ģr(sh©¬)ķgŻ¼Å─Č°╝ė┐ņĘ■äš(w©┤)╗ųÅ═(f©┤)Ą─╦┘Č╚ĪŻ
▓óąą╗žĘ┼
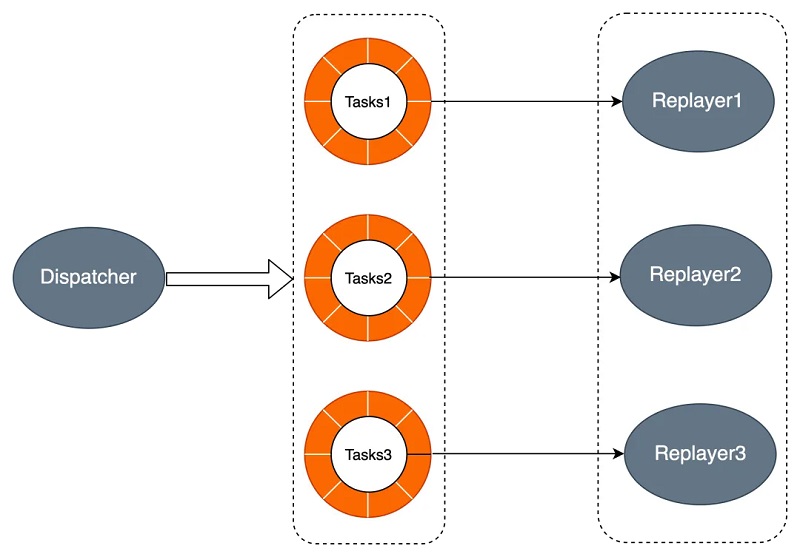
│²┴╦╔Ž╩÷ā╔³c(di©Żn)Ż¼PolarDB═¼Ģr(sh©¬)═©▀^(gu©░)▓óąą╗žĘ┼╝ė╦┘HAĢr(sh©¬)ROĄ─╗žĘ┼╦┘Č╚Ż¼įŁ└Ē╚ńŽ┬╦∙╩ŠĪŻDispatcher▀M(j©¼n)│╠īó╗žĘ┼╚╬äš(w©┤)═Ų╦═ĄĮĖ„éĆ(g©©)▀M(j©¼n)│╠Ą─╚╬äš(w©┤)ĻĀ(du©¼)┴ąŻ¼▀M(j©¼n)│╠ĮMųą▀M(j©¼n)│╠ūx╚ĪĖ„ūį╚╬äš(w©┤)ĻĀ(du©¼)┴ąųąĄ─╚╬äš(w©┤)▀M(j©¼n)ąą╗žĘ┼ĪŻ
PolarDB═©▀^(gu©░)ā×(y©Łu)╗»RO╣Ø(ji©”)³c(di©Żn)Ą─ā╚(n©©i)┤µ═¼▓Į▀^(gu©░)│╠Ż¼śO┤¾ĄžĮĄĄ═┴╦RW┼cROų«ķgĄ─čė▀tŻ¼═¼Ģr(sh©¬)═©▀^(gu©░)Online Promote║═▓óąą╗žĘ┼╝ė╦┘┴╦HAĢr(sh©¬)Ę■äš(w©┤)Ą─╗ųÅ═(f©┤)╦┘Č╚Ż¼┐╔į┌▒ŻšŽRPO×ķ0Ą─═¼Ģr(sh©¬)Ż¼ęį▌^Ą═Ą─RTOīŹ(sh©¬)¼F(xi©żn)å╬éĆ(g©©)┐╔ė├ģ^(q©▒)ā╚(n©©i)Ą─Ė▀┐╔ė├ĪŻ┤╦═ŌŻ¼PolarDB╗∙ė┌Cluster ManagerŻ¼▀Ć┐╔īŹ(sh©¬)¼F(xi©żn)ī”(du©¼)╝»╚║ĀŅæB(t©żi)Ą─ų„äė(d©░ng)▒O(ji©Īn)┐ž╝░ī”(du©¼)╣╩šŽĄ─┐ņ╦┘Öz£y(c©©)Ż¼╠ß╣®ūįäė(d©░ng)╗»Ą─╣╩šŽ╠Ä└Ē╗ųÅ═(f©┤)─▄┴”Ż¼▒ŻūCĘ■äš(w©┤)Ą─▀B└m(x©┤)┐╔ė├ąįŻ¼Ž┬├µįö╝Ü(x©¼)ĮķĮBCluster ManagerĄ─īŹ(sh©¬)¼F(xi©żn)ĪŻ
Cluster Manager
Cluster Manageržō(f©┤)ž¤(z©”)╝»╚║╝░┼õų├╣▄└ĒŻ¼ūįäė(d©░ng)╗»Ą─ŠSūo(h©┤)╝»╚║Ą─Ė▀┐╔ė├Ż¼Ųõā╚(n©©i)▓┐─ŻēK╚ńŽ┬Ż║
1ĪóDetector╠Į£y(c©©)─ŻēK═©▀^(gu©░)ą─╠°šł(q©½ng)Ū¾╠Į£y(c©©)öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Ą─┐╔ė├ąįŻ¼─¼šJ(r©©n)×ķ3s│¼Ģr(sh©¬)Ż¼«ö(d©Īng)░l(f©Ī)╔·│¼Ģr(sh©¬)Ģr(sh©¬)Ż¼═¼Ģr(sh©¬)Ģ■(hu©¼)ėąę╗éĆ(g©©)backupą─╠°▀M(j©¼n)ąą▌oų·øQ▓▀Ż¼▒▄├Ō╠ž╩ŌŪķørī¦(d©Żo)ų┬š`┼ąŻ¼backupą─╠°─¼šJ(r©©n)│¼Ģr(sh©¬)×ķ60s;
3ĪóCollector▓╔╝»─ŻēK½@╚ĪĖ„éĆ(g©©)ŠSČ╚Ą─īŹ(sh©¬)Ģr(sh©¬)▒O(ji©Īn)┐žą┼ŽóŻ¼░³└©▓┘ū„ŽĄĮy(t©»ng)Īó╚▌Ų„Īó┤µā”(ch©│)╝░öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)ā╚(n©©i)║╦Ą─ČÓéĆ(g©©)ųĖś╦(bi©Īo)Ż¼ĮY(ji©”)║Ž╦∙ėąųĖś╦(bi©Īo)╝┤┐╔Ą├ĄĮ«ö(d©Īng)Ū░öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)īŹ(sh©¬)└²Ą─▀\(y©┤n)ąąĀŅæB(t©żi)Ż¼ė├ė┌Ęų╬÷╝░øQ▓▀;
4ĪóDecisionøQ▓▀─ŻēK╗∙ė┌╔Ž╩÷½@╚ĪĄ─īŹ(sh©¬)└²▀\(y©┤n)ąąĀŅæB(t©żi)▀M(j©¼n)ąąøQ▓▀Ż¼╚ńī”(du©¼)öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)īŹ(sh©¬)└²╣Ø(ji©”)³c(di©Żn)╝░MaxScale╣Ø(ji©”)³c(di©Żn)Ą─┐╔ė├ąį▀M(j©¼n)ąąøQ▓▀Ż¼ī”(du©¼)īŹ(sh©¬)└²╝░ŲõĀŅæB(t©żi)ūāĖ³▀M(j©¼n)ąąøQ▓▀;
5ĪóActionł╠(zh©¬)ąą─ŻēKīŹ(sh©¬)╩®DecisionøQ▓▀─ŻēKŽ┬░l(f©Ī)Ą─øQ▓▀Ż¼╚ńųžåóöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)╣Ø(ji©”)³c(di©Żn)Ż¼▀M(j©¼n)ąąHAŪąōQŻ¼ī”(du©¼)īŹ(sh©¬)└²▀M(j©¼n)ąąų╗ūxµiČ©Ą╚;
6ĪóPlugin▓Õ╝■─ŻēK½@╚ĪManager╠ß╣®Ą─╝»╚║╣Ø(ji©”)³c(di©Żn)═ž?f©┤)õą┼Žó╝░ž?f©┤)▌dŪķørŻ¼▒Ńė┌Ųõī”(du©¼)ūį╔ĒĄ─ąą×ķ▀M(j©¼n)ąąš{(di©żo)š¹ĪŻ
▓┐ĘųĄõą═Ą─«É│Ż╣╩šŽł÷(ch©Żng)Š░╚ńŽ┬Ż¼Cluster ManagerĢ■(hu©¼)ę└ō■(j©┤)ČÓŠSČ╚Ą─ą┼Žó▀M(j©¼n)ąą┼ąöÓ┼cøQ▓▀Ż║
«É│Żł÷(ch©Żng)Š░ ĪĪĪĪøQ▓▀öĄ(sh©┤)ō■(j©┤)
ėŗ(j©¼)╦Ń╣Ø(ji©”)³c(di©Żn)Õ┤ÖC(j©®) ĪĪĪĪČÓŠSČ╚│¼Ģr(sh©¬)Īó╚▌Ų„ų„ÖC(j©®)öĄ(sh©┤)ō■(j©┤)▒▄├Ōš`┼ą
ėŗ(j©¼)╦Ń╣Ø(ji©”)³c(di©Żn)ŠW(w©Żng)Įj(lu©░)ųąöÓ ĪĪĪĪČÓŠSČ╚│¼Ģr(sh©¬)
ėŗ(j©¼)╦Ń╣Ø(ji©”)³c(di©Żn)ŠW(w©Żng)┐©╣╩šŽ ĪĪĪĪČÓŠSČ╚│¼Ģr(sh©¬)ĪóŠW(w©Żng)┐©ĀŅæB(t©żi)▒O(ji©Īn)┐ž
ėŗ(j©¼)╦Ń╣Ø(ji©”)³c(di©Żn)┤µā”(ch©│)Æņ▌düG╩¦ ĪĪĪĪą─╠°│¼Ģr(sh©¬)Īó┤µā”(ch©│)Æņ▌dĀŅæB(t©żi)▒O(ji©Īn)┐ž
öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)ā╚(n©©i)║╦Crash ĪĪĪĪą─╠°ĀŅæB(t©żi)
öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)ā╚(n©©i)║╦OOM ĪĪĪĪą─╠°ĀŅæB(t©żi)Īóā╚(n©©i)┤µĀŅæB(t©żi)
öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)IO hang ĪĪĪĪą─╠°│¼Ģr(sh©¬)ĪóĄ╚┤²╩┬╝■ĪóIOųĖś╦(bi©Īo)øQ▓▀
ėŗ(j©¼)╦Ń╣Ø(ji©”)³c(di©Żn)üG░³10% ĪĪĪĪą─╠°▓╗│ų└m(x©┤)ąį│¼Ģr(sh©¬)
ėŗ(j©¼)╦Ń╣Ø(ji©”)³c(di©Żn)ŠW(w©Żng)Įj(lu©░)čė▀t100ms ĪĪĪĪą─╠°▓╗│ų└m(x©┤)ąį│¼Ģr(sh©¬)
RO╗žĘ┼čė▀t ĪĪĪĪÅ═(f©┤)ųŲĀŅæB(t©żi)Īóbuffer╩╣ė├┬╩
«ö(d©Īng)╠Į£y(c©©)ĄĮ╣Ø(ji©”)³c(di©Żn)▓╗┐╔ė├Ģr(sh©¬)Ż¼Cluster ManagerĢ■(hu©¼)▀M(j©¼n)ę╗▓ĮŽ┬░l(f©Ī)╗ųÅ═(f©┤)▓▀┬įŻ║
1Īó╚¶RO╣Ø(ji©”)³c(di©Żn)▓╗┐╔ė├Ż¼ätī”(du©¼)RO╣Ø(ji©”)³c(di©Żn)▀M(j©¼n)ąąųžĮ©;
2Īó╚¶RW╣Ø(ji©”)³c(di©Żn)▓╗┐╔ė├Ż¼ät▀M(j©¼n)ę╗▓Į┼ąöÓRO╣Ø(ji©”)³c(di©Żn)ĀŅæB(t©żi)Ż¼╚¶RO╣Ø(ji©”)³c(di©Żn)┐╔ė├Ż¼ätė|░l(f©Ī)HAŪąōQŻ¼║Y▀xĘ¹║Žę¬Ū¾Ą─ROŻ¼īóŲõ╠ß╔²×ķRWŻ¼▓óųžĮ©RO;
3Īó╚¶RW┼cRO╣Ø(ji©”)³c(di©Żn)═¼Ģr(sh©¬)▓╗┐╔ė├Ż¼ätŽ╚▀M(j©¼n)ąąųžåóŻ¼╚¶RW┼cRO╣Ø(ji©”)³c(di©Żn)│ų└m(x©┤)▓╗┐╔ė├Ż¼ät▀M(j©¼n)ę╗▓Į┼ąöÓStandby╣Ø(ji©”)³c(di©Żn)╩Ūʱ┐╔ė├Ż¼╚¶┐╔ė├ätė|░l(f©Ī)ŪąōQŻ¼║Y▀xĘ¹║Žę¬Ū¾Ą─StandbyŻ¼īóŲõ╠ß╔²×ķRWŻ¼▓óųžĮ©StandbyĪŻ
Cluster ManagerīŹ(sh©¬)¼F(xi©żn)┴╦ūįäė(d©░ng)╗»Ą─▒O(ji©Īn)┐žĪóŪąōQøQ▓▀ĪóŪąōQ┴„│╠Ż¼į┌▓╗ąĶę¬ė├æ¶(h©┤)Ė╔ŅA(y©┤)Ą─ŪķørŽ┬Ż¼┤_▒Ż┴╦RTOĪŻCluster Manager┐╔ī”(du©¼)ČÓéĆ(g©©)┐╔ė├ģ^(q©▒)Ą─īŹ(sh©¬)└²ĀŅæB(t©żi)▀M(j©¼n)ąą▒O(ji©Īn)┐žŻ¼īŹ(sh©¬)¼F(xi©żn)AZā╚(n©©i)/┐ńAZ/┐ńė“╝ē(j©¬)äeĄ─ūįäė(d©░ng)╗»╣╩šŽÖz£y(c©©)╝░╗ųÅ═(f©┤)Ż¼Ž┬├µī”(du©¼)┐ń┐╔ė├ģ^(q©▒)Ą─ėŗ(j©¼)╦Ń╝»╚║ķgĄ─Ė▀┐╔ė├īŹ(sh©¬)¼F(xi©żn)▀M(j©¼n)ąąĮķĮBĪŻ
ėŗ(j©¼)╦Ń╝»╚║Ė▀┐╔ė├
DataMax╣Ø(ji©”)³c(di©Żn)
PolarDB═©▀^(gu©░)į÷╝ėROų╗ūx╣Ø(ji©”)³c(di©Żn)īŹ(sh©¬)¼F(xi©żn)å╬éĆ(g©©)AZā╚(n©©i)ėŗ(j©¼)╦Ń╣Ø(ji©”)³c(di©Żn)Ą─Ė▀┐╔ė├Ż¼═¼Ģr(sh©¬)į÷╝ėDataMax╣Ø(ji©”)³c(di©Żn)üĒ(l©ói)Ė³Ė▀ą¦ĄžīŹ(sh©¬)¼F(xi©żn)ėŗ(j©¼)╦Ń╝»╚║Ą─Ė▀┐╔ė├ĪŻPolarDB╗∙ė┌╬’└Ē┴„Å═(f©┤)ųŲīŹ(sh©¬)¼F(xi©żn)ų„Äņ(k©┤)┼céõÄņ(k©┤)ų«ķgĄ─öĄ(sh©┤)ō■(j©┤)═¼▓ĮŻ¼ų„Äņ(k©┤)┼céõÄņ(k©┤)Ą─┴„Å═(f©┤)ųŲ─Ż╩Į░³║¼═¼▓Į╝░«É▓Įā╔ĘNŻ║
1Īó«É▓Į─Ż╩ĮŽ┬Ż¼ų„Äņ(k©┤)Ą─╩┬äš(w©┤)╠ßĮ╗āHąĶĄ╚┤²ī”(du©¼)æ¬(y©®ng)╚šųŠīæ(xi©¦)╚ļ▒ŠĄž┤┼▒P(p©ón)╬─╝■ųą║¾Ż¼╝┤┐╔▀M(j©¼n)ąąų«║¾Ą─╠ßĮ╗▓┘ū„Ż¼éõÄņ(k©┤)Ą─ĀŅæB(t©żi)ī”(du©¼)ų„Äņ(k©┤)Ą─ąį─▄¤o(w©▓)ė░ĒæĪŻĄ½«É▓Į─Ż╩ĮŽ┬¤o(w©▓)Ę©▒ŻūCRPO=0Ż¼éõÄņ(k©┤)ŽÓ▌^ų„Äņ(k©┤)┤µį┌ę╗Č©Ą─čė▀tŻ¼╚¶ų„Äņ(k©┤)╦∙į┌Ą─╝»╚║│÷¼F(xi©żn)╣╩šŽŻ¼┤╦Ģr(sh©¬)ŪąōQų┴éõÄņ(k©┤)┐╔─▄┤µį┌öĄ(sh©┤)ō■(j©┤)üG╩¦;
2Īó═¼▓Į─Ż╩Į░³║¼▓╗═¼Ą─╝ē(j©¬)äeŻ¼┐╔═©▀^(gu©░)synchronous_commitģóöĄ(sh©┤)▀M(j©¼n)ąąįO(sh©©)ų├Ż¼░³└©Ż║
1)remote_writeŻ║įō─Ż╩ĮŽ┬Ż¼ų„Äņ(k©┤)Ą─╩┬äš(w©┤)╠ßĮ╗ąĶĄ╚┤²ī”(du©¼)æ¬(y©®ng)╚šųŠīæ(xi©¦)╚ļų„Äņ(k©┤)┤┼▒P(p©ón)╬─╝■╝░éõÄņ(k©┤)Ą─ŽĄĮy(t©»ng)ŠÅ┤µųą║¾Ż¼▓┼─▄▀M(j©¼n)ąąų«║¾Ą─╩┬äš(w©┤)╠ßĮ╗▓┘ū„;
2)onŻ║įō─Ż╩ĮŽ┬Ż¼ų„Äņ(k©┤)Ą─╩┬äš(w©┤)╠ßĮ╗ąĶĄ╚┤²ī”(du©¼)æ¬(y©®ng)╚šųŠČ╝ęčīæ(xi©¦)╚ļų„Äņ(k©┤)╝░éõÄņ(k©┤)Ą─┤┼▒P(p©ón)╬─╝■ųą║¾Ż¼▓┼─▄▀M(j©¼n)ąąų«║¾Ą─╩┬äš(w©┤)╠ßĮ╗▓┘ū„;
3)remote_applyŻ║įō─Ż╩ĮŽ┬Ż¼ų„Äņ(k©┤)Ą─╩┬äš(w©┤)╠ßĮ╗ąĶĄ╚┤²ī”(du©¼)æ¬(y©®ng)╚šųŠīæ(xi©¦)╚ļų„Äņ(k©┤)╝░éõÄņ(k©┤)Ą─┤┼▒P(p©ón)╬─╝■ųąŻ¼═¼Ģr(sh©¬)éõÄņ(k©┤)ęčĮø(j©®ng)╗žĘ┼═Ļī”(du©¼)æ¬(y©®ng)╚šųŠ╩╣Ųõī”(du©¼)éõÄņ(k©┤)╔ŽĄ─▓ķįā(x©▓n)┐╔ęŖ(ji©żn)║¾Ż¼▓┼─▄▀M(j©¼n)ąąų«║¾Ą─╩┬äš(w©┤)╠ßĮ╗▓┘ū„ĪŻ
═¼▓Į─Ż╩Į▒ŻūC┴╦ų„Äņ(k©┤)Ą─╩┬äš(w©┤)╠ßĮ╗▓┘ū„ąĶĄ╚┤²éõÄņ(k©┤)Įė╩šĄĮī”(du©¼)æ¬(y©®ng)Ą─╚šųŠöĄ(sh©┤)ō■(j©┤)ų«║¾▓┼┐╔ł╠(zh©¬)ąąŻ¼Å─Č°īŹ(sh©¬)¼F(xi©żn)┴╦ų„Äņ(k©┤)┼céõÄņ(k©┤)ų«ķgĄ─┴ŃöĄ(sh©┤)ō■(j©┤)üG╩¦Ż¼┐╔▒ŻūCRPO=0ĪŻĄ½═¼Ģr(sh©¬)Ż¼įō─Ż╩ĮŽ┬ų„Äņ(k©┤)Ą─╩┬äš(w©┤)╠ßĮ╗▓┘ū„ę└┘ć(l©żi)éõÄņ(k©┤)Ą─╚šųŠĮė╩šĮY(ji©”)╣¹Ż¼ę“┤╦╚¶ų„éõų«ķgŠÓļx▌^▀h(yu©Żn)ī¦(d©Żo)ų┬é„▌öčė▀t▌^┤¾Ģr(sh©¬)Ż¼═¼▓Į─Ż╩ĮĢ■(hu©¼)ī”(du©¼)ų„Äņ(k©┤)Ą─ąį─▄ĦüĒ(l©ói)ė░Ēæ;śOČ╦ŪķørŽ┬Ż¼╚¶éõÄņ(k©┤)«É│ŻcrashŻ¼ät┤╦Ģr(sh©¬)ų„Äņ(k©┤)ätĢ■(hu©¼)ę╗ų▒ūĶ╚¹į┌Ą╚┤²éõÄņ(k©┤)Ą─▀^(gu©░)│╠ųąŻ¼ī¦(d©Żo)ų┬¤o(w©▓)Ę©š²│Ż╠ß╣®Ę■äš(w©┤)ĪŻ
ßśī”(du©¼)é„Įy(t©»ng)ų„éõ─Ż╩ĮŽ┬═¼▓ĮÅ═(f©┤)ųŲī”(du©¼)ų„Äņ(k©┤)ąį─▄ė░Ēæ▌^┤¾Ą─å¢(w©©n)Ņ}Ż¼PolarDBą┬į÷DataMax╣Ø(ji©”)³c(di©Żn)ė├ė┌īŹ(sh©¬)¼F(xi©żn)▀h(yu©Żn)│╠═¼▓ĮŻ¼╚ńŽ┬Ż║
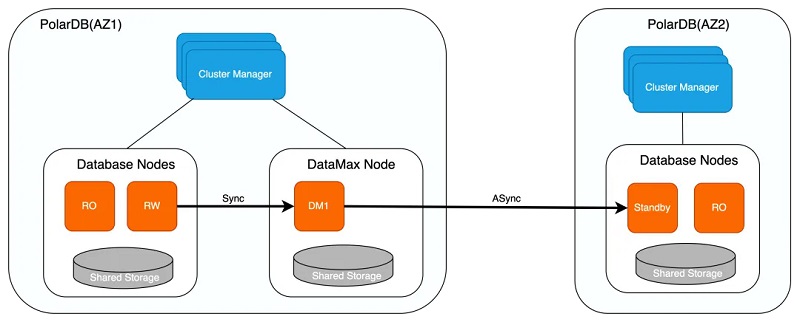
1ĪóDataMax╣Ø(ji©”)³c(di©Żn)āH▒Ż┤µWAL╚šųŠ╬─╝■Ż¼▓ó▓╗ī”(du©¼)╚šųŠ▀M(j©¼n)ąą╗žĘ┼▓┘ū„Ż¼▓╗▒Ż┤µRW╣Ø(ji©”)³c(di©Żn)Ą─öĄ(sh©┤)ō■(j©┤)╬─╝■Ż¼ĮĄĄ═┤µā”(ch©│)│╔▒Š;
2ĪóDataMax╣Ø(ji©”)³c(di©Żn)┼cRW╣Ø(ji©”)³c(di©Żn)öĄ(sh©┤)ō■(j©┤)▓╗╣▓ŽĒŻ¼ā╔š▀Ą─┤µā”(ch©│)įO(sh©©)éõ▒╦┤╦Ė¶ļxŻ¼ęįĘ└ų╣ėŗ(j©¼)╦Ń╝»╚║┤µā”(ch©│)«É│Żī¦(d©Żo)ų┬Ą─RW╣Ø(ji©”)³c(di©Żn)┼cDataMax╣Ø(ji©”)³c(di©Żn)▒Ż┤µĄ─╚šųŠČ╝üG╩¦;
3ĪóDataMax╣Ø(ji©”)³c(di©Żn)┼cRW╣Ø(ji©”)³c(di©Żn)ų«ķg×ķ═¼▓ĮÅ═(f©┤)ųŲ─Ż╩ĮŻ¼┤_▒ŻRPO=0Ż¼DataMax▓┐╩į┌ŠÓļxRW╣Ø(ji©”)³c(di©Żn)▌^Į³Ą─ģ^(q©▒)ė“Ż¼═©│Ż┼cRW╣Ø(ji©”)³c(di©Żn)╬╗ė┌═¼ę╗┐╔ė├ģ^(q©▒)Ż¼ęį£pąĪ╚šųŠ═¼▓Įī”(du©¼)ų„Äņ(k©┤)ĦüĒ(l©ói)Ą─ąį─▄ė░Ēæ;
4ĪóDataMax╣Ø(ji©”)³c(di©Żn)īóŲõūį╔ĒĮė╩š╚šųŠ░l(f©Ī)╦═ų┴Ųõ╦¹┐╔ė├ģ^(q©▒)Ą─Standby╣Ø(ji©”)³c(di©Żn)Ż¼Standby╣Ø(ji©”)³c(di©Żn)Įė╩š▓ó╗žĘ┼DataMax╣Ø(ji©”)³c(di©Żn)Ą─╚šųŠīŹ(sh©¬)¼F(xi©żn)┼cRW╣Ø(ji©”)³c(di©Żn)Ą─▀h(yu©Żn)│╠═¼▓ĮŻ¼Standby╣Ø(ji©”)³c(di©Żn)┼cDataMax╣Ø(ji©”)³c(di©Żn)ų«ķg┐╔įO(sh©©)ų├×ķ«É▓Į┴„Å═(f©┤)ųŲ─Ż╩ĮŻ¼═©▀^(gu©░)DataMax╣Ø(ji©”)³c(di©Żn)┐╔Ęų┴„RW╣Ø(ji©”)³c(di©Żn)Ž“ČÓéĆ(g©©)éõĘ▌öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)é„▌ö╚šųŠĄ─ķ_(k©Īi)õN(xi©Īo)ĪŻ
╝»╚║Ė▀┐╔ė├
╚ńŽ┬Ż¼╚¶RW╣Ø(ji©”)³c(di©Żn)┼cRO╣Ø(ji©”)³c(di©Żn)═¼Ģr(sh©¬)«É│ŻŻ¼╗“┤µā”(ch©│)¤o(w©▓)Ę©╠ß╣®Ę■äš(w©┤)Ģr(sh©¬)Ż¼ät┐╔īó╬╗ė┌▓╗═¼┐╔ė├ģ^(q©▒)Ą─Standby╣Ø(ji©”)³c(di©Żn)╠ß╔²×ķRW╣Ø(ji©”)³c(di©Żn)Ż¼▒ŻūCĘ■äš(w©┤)Ą─┐╔ė├ąįĪŻį┌īóStandby╣Ø(ji©”)³c(di©Żn)╠ß╔²×ķRW╣Ø(ji©”)³c(di©Żn)▓óŽ“═Ō╠ß╣®Ę■äš(w©┤)ų«Ū░Ż¼Ģ■(hu©¼)┤_šJ(r©©n)Standby╣Ø(ji©”)³c(di©Żn)╩ŪʱęčÅ─DataMax╣Ø(ji©”)³c(di©Żn)└Ł╚Ī═Ļ«ģ╦∙ėą╚šųŠŻ¼ė╔ė┌DataMax╣Ø(ji©”)³c(di©Żn)┼cRW╣Ø(ji©”)³c(di©Żn)×ķ═¼▓ĮÅ═(f©┤)ųŲŻ¼ę“┤╦┐╔▒ŻūCįōł÷(ch©Żng)Š░Ž┬RPO=0ĪŻ
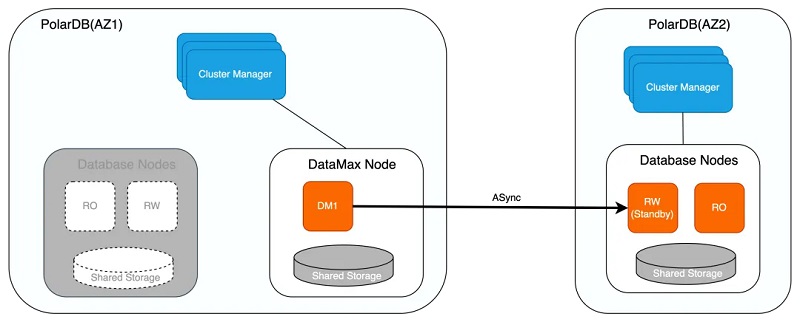
╚¶DataMax╣Ø(ji©”)³c(di©Żn)«É│ŻŻ¼ätā×(y©Łu)Ž╚ćLįćųžåó▀M(j©¼n)ąą╗ųÅ═(f©┤)Ż¼╚¶ųžåó╩¦öĪätī”(du©¼)Ųõ▀M(j©¼n)ąąųžĮ©Ż¼ę“DataMax╣Ø(ji©”)³c(di©Żn)┼cRW╣Ø(ji©”)³c(di©Żn)┤µā”(ch©│)▒╦┤╦Ė¶ļxŻ¼ę“┤╦ā╔š▀öĄ(sh©┤)ō■(j©┤)▓ó▓╗╗źŽÓė░ĒæŻ¼┤╦═ŌDataMax╣Ø(ji©”)³c(di©Żn)┐╔═¼śė▓╔╚Īėŗ(j©¼)╦Ń┤µā”(ch©│)Ęųļx╝▄śŗ(g©░u)Ż¼┤_▒ŻDataMax╣Ø(ji©”)³c(di©Żn)Ą─«É│Ż▓╗Ģ■(hu©¼)ī¦(d©Żo)ų┬Ųõ┤µā”(ch©│)Ą─WAL╚šųŠöĄ(sh©┤)ō■(j©┤)üG╩¦ĪŻ
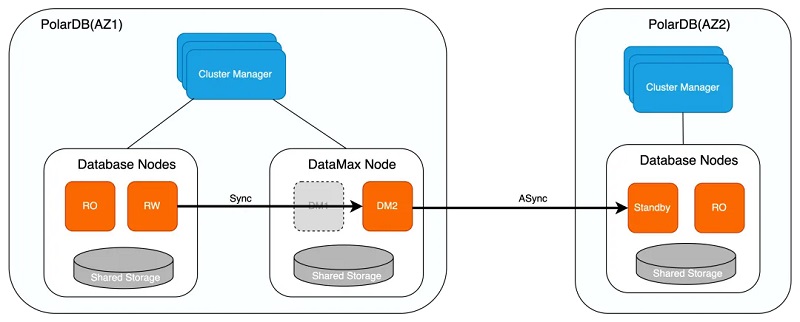
ŅÉ(l©©i)╦ŲĄžŻ¼DataMax╣Ø(ji©”)³c(di©Żn)īŹ(sh©¬)¼F(xi©żn)┴╦╚ńŽ┬ÄūĘN╚šųŠ═¼▓Į─Ż╩ĮŻ¼ė├æ¶(h©┤)┐╔ęįĖ∙ō■(j©┤)Š▀¾wśI(y©©)äš(w©┤)ąĶŪ¾▀M(j©¼n)ąąŽÓæ¬(y©®ng)┼õų├Ż║
1ĪóūŅ┤¾▒Żūo(h©┤)─Ż╩Į
1)įō─Ż╩ĮŽ┬Ż¼DataMax╣Ø(ji©”)³c(di©Żn)┼cRW╣Ø(ji©”)³c(di©Żn)▀M(j©¼n)ąą╚šųŠÅŖ(qi©óng)═¼▓ĮŻ¼┤_▒ŻRPO=0;
2)╚¶DataMax╣Ø(ji©”)³c(di©Żn)ę“ŠW(w©Żng)Įj(lu©░)╗“ė▓╝■╣╩šŽ¤o(w©▓)Ę©╠ß╣®Ę■äš(w©┤)Ż¼RW╣Ø(ji©”)³c(di©Żn)ę▓Ģ■(hu©¼)ę“┤╦ūĶ╚¹Č°¤o(w©▓)Ę©ī”(du©¼)═Ō╠ß╣®Ę■äš(w©┤);
2ĪóūŅ┤¾ąį─▄─Ż╩Į
1)įō─Ż╩ĮŽ┬Ż¼DataMax╣Ø(ji©”)³c(di©Żn)┼cRW╣Ø(ji©”)³c(di©Żn)▀M(j©¼n)ąą╚šųŠ«É▓Į┴„Å═(f©┤)ųŲŻ¼DataMax╣Ø(ji©”)³c(di©Żn)▓╗ī”(du©¼)RW╣Ø(ji©”)³c(di©Żn)ąį─▄ĦüĒ(l©ói)ė░ĒæŻ¼DataMax╣Ø(ji©”)³c(di©Żn)«É│Żę▓▓╗Ģ■(hu©¼)ė░ĒæRW╣Ø(ji©”)³c(di©Żn)Ą─Ę■äš(w©┤);
2)╚¶RW╣Ø(ji©”)³c(di©Żn)Ž┬Ą─┤µā”(ch©│)╗“?q©▒)”æ?y©®ng)Ą─╝»╚║░l(f©Ī)╔·╣╩šŽŻ¼ät┐╔─▄ī¦(d©Żo)ų┬üG╩¦▌^ČÓöĄ(sh©┤)ō■(j©┤)Ż¼¤o(w©▓)Ę©┤_▒ŻRPO=0;
3ĪóūŅ┤¾Ė▀┐╔ė├─Ż╩Į
1)įō─Ż╩ĮŽ┬Ż¼«ö(d©Īng)DataMax╣Ø(ji©”)³c(di©Żn)š²│Ż╣żū„Ģr(sh©¬)Ż¼DataMax╣Ø(ji©”)³c(di©Żn)┼cRW╣Ø(ji©”)³c(di©Żn)▀M(j©¼n)ąą╚šųŠÅŖ(qi©óng)═¼▓ĮŻ¼╝┤×ķūŅ┤¾▒Żūo(h©┤)─Ż╩Į;
2)╚¶DataMax╣Ø(ji©”)³c(di©Żn)«É│ŻŻ¼ätRW╣Ø(ji©”)³c(di©Żn)īó═¼▓Į─Ż╩ĮĮĄ╝ē(j©¬)×ķūŅ┤¾ąį─▄─Ż╩ĮŻ¼▒ŻūCRW╣Ø(ji©”)³c(di©Żn)Ę■äš(w©┤)Ą─│ų└m(x©┤)┐╔ė├;
3)«ö(d©Īng)DataMax╣Ø(ji©”)³c(di©Żn)╗ųÅ═(f©┤)š²│Ż║¾Ż¼ätRW╣Ø(ji©”)³c(di©Żn)į┘┤╬īó«É▓Į─Ż╩Į╠ß╔²×ķūŅ┤¾▒Żūo(h©┤)─Ż╩ĮŻ¼▒▄├Ō╚šųŠöĄ(sh©┤)ō■(j©┤)│÷¼F(xi©żn)▌^ČÓüG╩¦ĪŻ
═©▀^(gu©░)DataMax╚šųŠųą└^╣Ø(ji©”)³c(di©Żn)ĮĄĄ═╚šųŠ═¼▓Įčė▀tĪóĘų┴„RW╣Ø(ji©”)³c(di©Żn)Ą─╚šųŠé„▌öē║┴”Ż¼┐╔į┌ąį─▄ĘĆ(w©¦n)Č©Ą─ŪķørŽ┬Ż¼▒ŻšŽ┐ńAZ/┐ńė“Ė▀┐╔ė├Ą─RPO=0ĪŻ
DMAĖ▀┐╔ė├
╔Ž╩÷ĘĮ╩ĮīŹ(sh©¬)¼F(xi©żn)Ą─╝»╚║Ė▀┐╔ė├ąĶ═©▀^(gu©░)╚šųŠÅŖ(qi©óng)═¼▓Į▒ŻūCRPO=0Ż¼«ö(d©Īng)│÷¼F(xi©żn)ŠW(w©Żng)Įj(lu©░)ČČäė(d©░ng)╗“éõĘ▌╣Ø(ji©”)³c(di©Żn)╣╩šŽĢr(sh©¬)Ż¼Č╝Ģ■(hu©¼)ī”(du©¼)╝»╚║Ą─┐╔ė├ąįĦüĒ(l©ói)ė░ĒæĪŻ┤╦═ŌŻ¼╝»╚║╣Ø(ji©”)³c(di©Żn)┐╔ė├ąįĄ─┼ąöÓ┼cĖ▀┐╔ė├øQ▓▀ę└┘ć(l©żi)Cluster ManagerŻ¼öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)╝»╚║▒Š╔Ē▓╗Š▀éõūįų„Ė▀┐╔ė├╗“ūį▀\(y©┤n)ŠS─▄┴”Ż¼ßśī”(du©¼)┤╦Ż¼PolarDB═¼Ģr(sh©¬)╠ß╣®┴╦╗∙ė┌DMAĄ─Ė▀┐╔ė├ą╬æB(t©żi)(╝┤╚²╣Ø(ji©”)³c(di©Żn)ą╬æB(t©żi))Ż¼Š▀¾w╚ńŽ┬Ż║
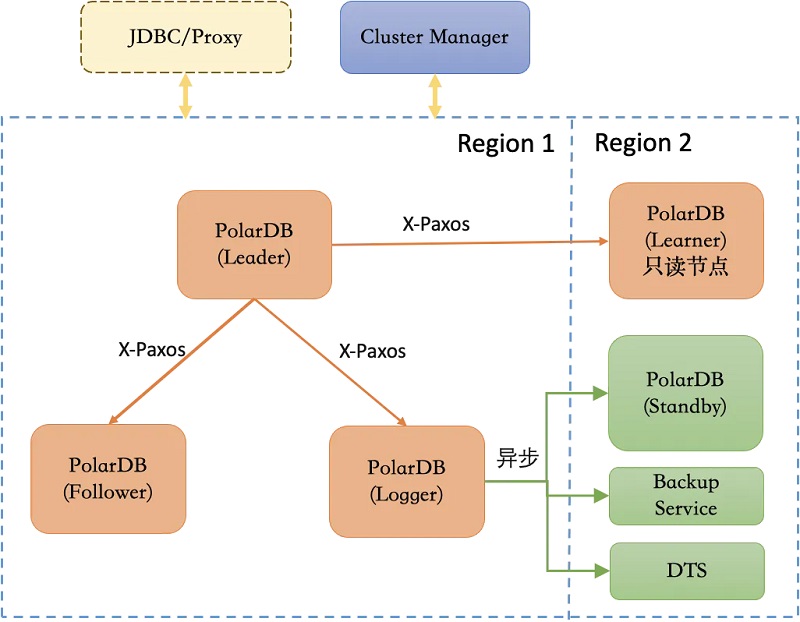
1ĪóDMAį┌öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)ā╚(n©©i)║╦ųąę²╚ļRaftĘų▓╝╩Įģf(xi©”)ūhŻ¼╗∙ė┌X-Paxos▀M(j©¼n)ąą╚šųŠ═¼▓ĮŻ¼═¼Ģr(sh©¬)┐╔ī”(du©¼)ų„éõ╣Ø(ji©”)³c(di©Żn)ĀŅæB(t©żi)▀M(j©¼n)ąą╣▄└Ē╝░ģf(xi©”)š{(di©żo)Ż¼į┌░l(f©Ī)╔·╣╩šŽĢr(sh©¬)▀M(j©¼n)ąąūįų„failoverŻ¼Š▀éõūįų„▀\(y©┤n)ŠS╝░ūįų„Ė▀┐╔ė├─▄┴”;
2ĪóDMAŠ▀éõ┐ńė“Ė▀┐╔ė├─▄┴”Ż¼┐╔╚▌╚╠N(y©┤n)/2 - 1éĆ(g©©)╣Ø(ji©”)³c(di©Żn)╣╩šŽŻ¼į┌╔┘öĄ(sh©┤)╣Ø(ji©”)³c(di©Żn)╣╩šŽĢr(sh©¬)╚į─▄▒ŻūCRPO=0;
3ĪóDMA┐╔īóX-Paxos┼cCluster ManagerŽÓĮY(ji©”)║ŽŻ¼▒ŻūC╣╩šŽ░l(f©Ī)╔·║¾Ą─RTO < 30s;
4ĪóDMAī”(du©¼)WAL╚šųŠ┴„║═Consensus╚šųŠ┴„Ą─é„▌öµ£┬Ę▀M(j©¼n)ąą┴╦ā×(y©Łu)╗»Ż¼┐╔īŹ(sh©¬)¼F(xi©żn)ąį─▄ōp║─ŽÓ▌^ė┌å╬ÖC(j©®)Ž┬ĮĄį┌10%ęį?x©▓n)?n©©i);
5ĪóDMA┐╔═¼Ģr(sh©¬)Įė╚ļDataMaxū„×ķŲõLogger╣Ø(ji©”)³c(di©Żn)Ż¼Å─Č°ĮĄĄ═▓┐╩│╔▒Š;┤╦═ŌįōĖ▀┐╔ė├╝▄śŗ(g©░u)▀Ć┐╔▒Ż│ų┼cé„Įy(t©»ng)ų„éõÅ═(f©┤)ųŲ╝░įŁėą╣żŠ▀╚ńDTSĄ─╝µ╚▌ĪŻ
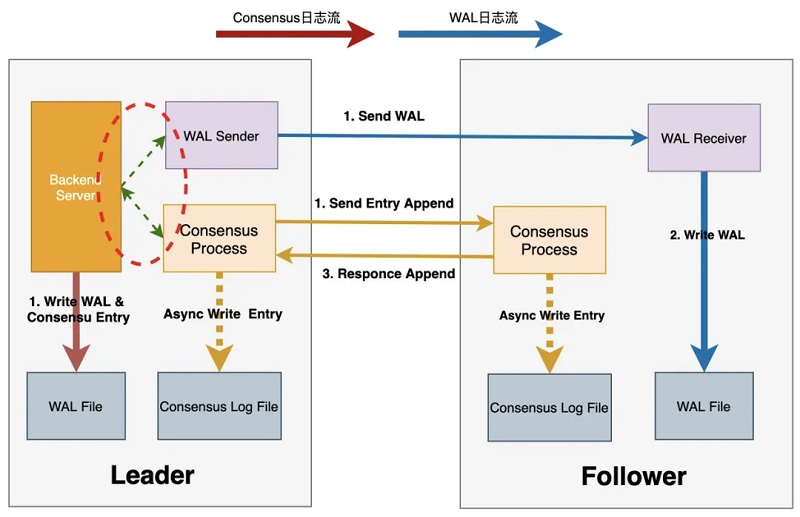
Consensus┼cWALļp╚šųŠ┴„
ę²╚ļX-Paxosų«║¾Ż¼DMAąĶ═©▀^(gu©░)Consensus╚šųŠÅ═(f©┤)ųŲüĒ(l©ói)ŠSūo(h©┤)╝»╚║öĄ(sh©┤)ō■(j©┤)Ą─ę╗ų┬ąįŻ¼═¼Ģr(sh©¬)ų„╣Ø(ji©”)³c(di©Żn)┼céõ╣Ø(ji©”)³c(di©Żn)ų«ķg▀ĆąĶę¬WAL╚šųŠÅ═(f©┤)ųŲüĒ(l©ói)īŹ(sh©¬)¼F(xi©żn)öĄ(sh©┤)ō■(j©┤)═¼▓ĮŻ¼ßśī”(du©¼)įōå¢(w©©n)Ņ}Ż¼DMA▓╔ė├┴╦Consensus log┼cWAL logļp╚šųŠ┴„Ą─ĘĮ╩ĮŻ║
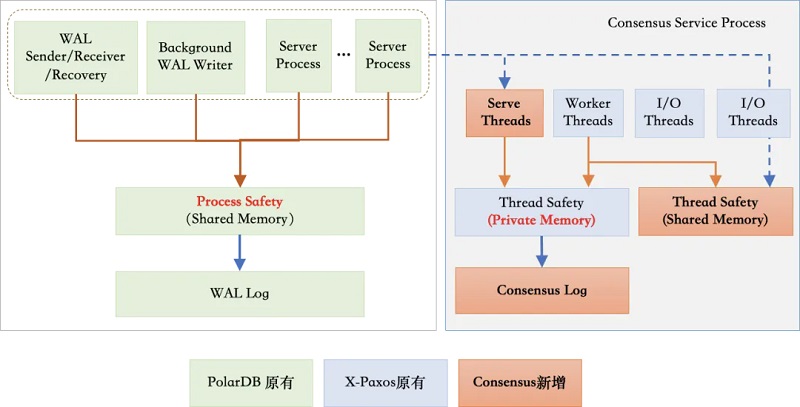
ŲõųąWAL╚šųŠÅ═(f©┤)ųŲ▓╔ė├įŁ╔·ĘĮ╩ĮŻ¼▒Ż│ų┼c╔ńģ^(q©▒)Ą─╝µ╚▌ąįĪŻConsensus╚šųŠ┼cWAL╚šųŠ¬Ü(d©▓)┴óŻ¼āHį┌Consensus╚šųŠųąėøõøWAL╚šųŠ╬╗³c(di©Żn)Ż¼Consensus╚šųŠ╠ßĮ╗│╔╣”╝┤┤·▒ĒŽÓæ¬(y©®ng)╬╗³c(di©Żn)ų«Ū░Ą─WAL╚šųŠę▓į┌ČÓöĄ(sh©┤)┼╔╔Ž╠ßĮ╗│╔╣”ĪŻ┤╦═ŌŻ¼DMA▀Ćī”(du©¼)ļp╚šųŠ┴„Ą─é„▌ö▀M(j©¼n)ąą┴╦ā×(y©Łu)╗»Ż¼╝ė┐ņ┴╦ļp╚šųŠ┴„Ą─é„▌ö╦┘Č╚Ż¼Å─Č°╠ß╔²┴╦š¹éĆ(g©©)╝»╚║Ą─┐╔ė├ąįŻ¼Ž┬├µįö╝Ü(x©¼)ī”(du©¼)┤╦▀M(j©¼n)ąąĮķĮBĪŻ
╚šųŠé„▌öµ£┬Ęā×(y©Łu)╗»
1ĪóDMAųąĄ─╚šųŠé„▌ö┴„│╠╚ńŽ┬Ż║
2ĪóLeader▀M(j©¼n)ąą╩┬äš(w©┤)╠ßĮ╗Ģr(sh©¬)Ż¼Ģ■(hu©¼)╔·│╔ī”(du©¼)æ¬(y©®ng)Ą─WAL╚šųŠ▓óīæ(xi©¦)╚ļWAL bufferųą;
3ĪóLeaderīóCommit Record LSNų«Ū░Ą─WAL╚šųŠ╦ó▒P(p©ón)Ż¼▓óåŠąčWalSender▀M(j©¼n)│╠īóWAL╚šųŠé„▌öų┴Ė„éĆ(g©©)Follower╣Ø(ji©”)³c(di©Żn)
4ĪóLeaderĄ─WalSender▀M(j©¼n)│╠īóWAL╚šųŠ░l(f©Ī)╦═ų┴Follower╣Ø(ji©”)³c(di©Żn);
5ĪóFollower╣Ø(ji©”)³c(di©Żn)Ą─WalReceiver▀M(j©¼n)│╠Įė╩šĄĮWAL╚šųŠ║¾īæ(xi©¦)╚ļ▒ŠĄžWAL╚šųŠ╬─╝■;
6ĪóLeader═©ų¬ConsensusĘ■äš(w©┤)▀M(j©¼n)│╠WAL╚šųŠęč┬õ▒P(p©ón)Ż¼▓óĄ╚┤²įōLSN╬╗³c(di©Żn)ČÓöĄ(sh©┤)┼╔│ųŠ├╗»│╔╣”;
7ĪóLeaderé„▌öWAL╚šųŠĄ─═¼Ģr(sh©¬)Ż¼ConsensusĘ■äš(w©┤)▀M(j©¼n)│╠╩╣ė├«ö(d©Īng)Ū░Flush LSN╔·│╔Consensus EntryŻ¼▓ó═©ų¬X-PaxosČÓöĄ(sh©┤)┼╔Å═(f©┤)ųŲEntry;
8ĪóLeaderĄ─X-Paxosš{(di©żo)ė├Consensus Log/Consensus serviceĮė┐┌▒ŠĄž│ųŠ├╗»Entryā╚(n©©i)╚▌;
9ĪóLeaderĄ─X-PaxosŽ“Ė„éĆ(g©©)Follower░l(f©Ī)╦═Consensus Entry;
10ĪóFollowerĄ─X-Paxosš{(di©żo)ė├Consensus Log/Consensus serviceĮė┐┌│ųŠ├╗»Entryā╚(n©©i)╚▌;
11ĪóFollowerĄ─X-PaxosŽ“Leader response▒ŠĄž│ųŠ├╗»Ą╚ą┼Žó;
LeaderĄ─X-PaxosćLįćĖ³ą┬commitIndexą┼ŽóŻ¼═Ų▀M(j©¼n)║¾åŠąčĄ╚┤²ųąĄ─▀M(j©¼n)│╠Ż¼═Ļ│╔╩┬äš(w©┤)╠ßĮ╗▓┘ū„ĪŻ
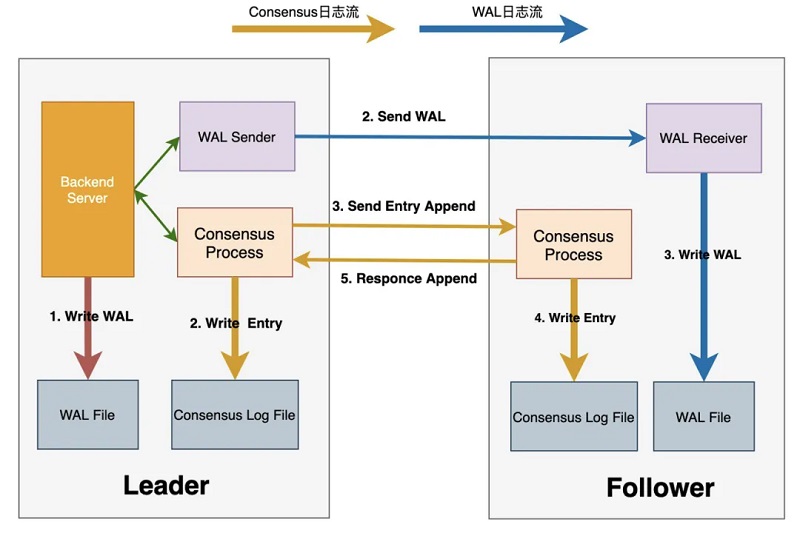
Å─╔Ž╩÷┴„│╠┐╔ų¬Ż¼š¹éĆ(g©©)╠ßĮ╗┴„│╠ų┴╔┘░³║¼╚²┤╬IO▓┘ū„╝░ā╔┤╬ŠW(w©Żng)Įj(lu©░)Į╗╗źŻ¼╝┤╔ŽłDųą1Ī½5Ą─▓Į¾EŻ¼ŲõųąWAL╚šųŠé„▌ö┼cĮė╩šŻ¼═¼Consensus╚šųŠĄ─╔·│╔┼cé„▌ö┐╔═¼▓Į▀M(j©¼n)ąąŻ¼įō╠ßĮ╗┴„│╠ī”(du©¼)╠ßĮ╗Ģr(sh©¬)čė╝░IOPSŠ∙Ģ■(hu©¼)ĦüĒ(l©ói)ę╗Č©Ą─ė░ĒæĪŻßśī”(du©¼)┤╦Ż¼DMA╩ūŽ╚īó│ųŠ├╗»Consensus EntryĄ─IO▓┘ū„┼cWAL Flush▓┘ū„▀M(j©¼n)ąą┴╦║Ž▓óĪŻ╚ńŽ┬Ż¼Leader╣Ø(ji©”)³c(di©Żn)į┌╔·│╔ī”(du©¼)æ¬(y©®ng)WAL╚šųŠĢr(sh©¬)Ż¼═¼Ģr(sh©¬)ę└ō■(j©┤)«ö(d©Īng)Ū░Commit Record LSN╔·│╔ī”(du©¼)æ¬(y©®ng)Consensus EntryŻ¼Ę┼╚ļConsensus Entry SLRUųąŻ¼ŅÉ(l©©i)╦ŲĄžŻ¼F(xi©żn)ollower╣Ø(ji©”)³c(di©Żn)┤_▒ŻŽÓæ¬(y©®ng)Ą─WAL╚šųŠęčĮė╩š═Ļ│╔║¾Ż¼īóConsensus Entryīæ(xi©¦)╚ļSLRUųąĪŻLeader╣Ø(ji©”)³c(di©Żn)╝░Follower╣Ø(ji©”)³c(di©Żn)│ųŠ├╗»EntryĄ─▓┘ū„Š∙┐╔«É▓Į▀M(j©¼n)ąąĪŻ
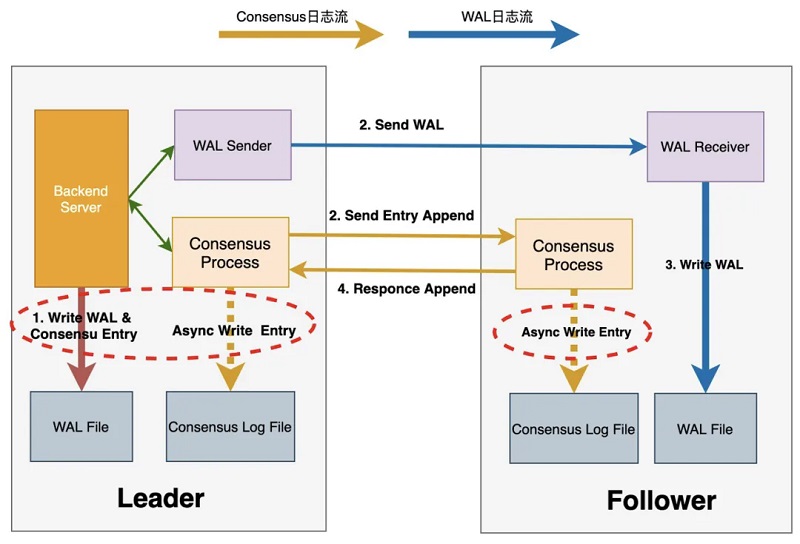
═¼Ģr(sh©¬)īóLeader FLush WALĄ─▓┘ū„┼c░l(f©Ī)╦═ļp╚šųŠ┴„Ą─▓┘ū„▓óąą╗»Ż¼ā╔š▀ĮY(ji©”)║Žų«║¾Ż¼š¹éĆ(g©©)╠ßĮ╗┴„│╠┬ĘÅĮ×ķŻ║
Max(1 I/O, (Max(1 RTT, 1 RTT +1 I/O) + 1 RTT)) = 1 I/O + 2 RTTŻ¼╝┤āH░³║¼ę╗┤╬IO▓┘ū„║═ā╔┤╬ŠW(w©Żng)Įj(lu©░)Į╗╗źĪŻį┌┤╦╗∙ĄA(ch©│)╔ŽŻ¼▀Ć┐╔īóFollower╣Ø(ji©”)³c(di©Żn)Ą─ŠW(w©Żng)Įj(lu©░)Įė╩š┼cWAL╚šųŠ┬õ▒P(p©ón)▓óąą╗»Ż¼Å─Č°▀M(j©¼n)ę╗▓Į╠ß╔²╚šųŠé„▌ö?sh©┤)─ąį─▄Ī?/p>
DMA╚²╣Ø(ji©”)³c(di©Żn)ą╬æB(t©żi)į┌▒ŻšŽRPO×ķ0Ą─═¼Ģr(sh©¬)Ż¼╠ß╔²┴╦ī”(du©¼)╝»╚║╣Ø(ji©”)³c(di©Żn)╣╩šŽĄ─╚▌╚╠│╠Č╚Ż¼╩╣Ą├╝»╚║ūį╔ĒŠ▀éõ┴╦ūįų„▀\(y©┤n)ŠS╝░ūįų„Ė▀┐╔ė├Ą──▄┴”Ż¼═¼Ģr(sh©¬)ĮY(ji©”)║Ž╚šųŠ╣Ø(ji©”)³c(di©Żn)┼c╚šųŠé„▌öā×(y©Łu)╗»Ż¼ĮĄĄ═┴╦Ė▀┐╔ė├Ą─īŹ(sh©¬)¼F(xi©żn)│╔▒Š┼cąį─▄ōp║─ĪŻ
┐éĮY(ji©”)
Ė▀┐╔ė├╩ŪįŲįŁ╔·öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)ųą▓╗┐╔╗“╚▒Ą─ę╗Łh(hu©ón)Ż¼▒Š╬─ī”(du©¼)PolarDB PostgreSQL░µĄ─Ė▀┐╔ė├╝▄śŗ(g©░u)╝░ÄūĘNĄõą═Ą─Ė▀┐╔ė├īŹ(sh©¬)¼F(xi©żn)ĘĮ░Ė▀M(j©¼n)ąą┴╦Ęų╬÷╝░ĮķĮBĪŻPolarDB PostgreSQL═©▀^(gu©░)RO/DataMax/DMAŻ¼┐╔īŹ(sh©¬)¼F(xi©żn)AZā╚(n©©i)/┐ńAZ/┐ńė“Ą─Ė▀┐╔ė├Ż¼▓óę²╚ļX-Paxos╩╣ā╚(n©©i)║╦Š▀ėą╣╩šŽĖąų¬╝░ūįų„▀\(y©┤n)ŠSĄ──▄┴”Ż¼═¼Ģr(sh©¬)ĮY(ji©”)║ŽCluster ManagerĖ∙ō■(j©┤)ČÓŠSĀŅæB(t©żi)┼õų├▓▀┬į▀M(j©¼n)ąą╣╩šŽ╠Į£y(c©©)║═Ž┬░l(f©Ī)╗ųÅ═(f©┤)øQ▓▀Ż¼ĮĄĄ═š`┼ą╠ß╔²╝»╚║ĘĆ(w©¦n)Č©ąįĪŻ┤╦═ŌŻ¼į┌▒ŻūCRPO=0Ą─═¼Ģr(sh©¬)Ż¼PolarDB PostgreSQL═©▀^(gu©░)WAL IndexĪóOnline PromoteĪóDMA╚šųŠé„▌öµ£┬Ęā×(y©Łu)╗»Ą╚ĘĮ╩Į▀M(j©¼n)ę╗▓Į╠ß╔²Å─╣╩šŽųą╗ųÅ═(f©┤)Ą─╦┘Č╚Ż¼▒M┐╔─▄Ąž▒ŻūCĘ■äš(w©┤)ūŅ╔┘ųąöÓ╗“▓╗ųąöÓĪŻ─┐Ū░PolarDB PostgreSQL╚įį┌│ų└m(x©┤)╠Į╦„╝░ā×(y©Łu)╗»Ż¼ęįį┌▒ŻšŽRPO=0Ą─╗∙ĄA(ch©│)╔ŽŻ¼ęįĖ³Ą═Ą─│╔▒ŠĪóĖ³┐ņĄ─╦┘Č╚ĪóĖ³╚½├µĄ─ą╬æB(t©żi)īŹ(sh©¬)¼F(xi©żn)ę╗¾w╗»ĪóŽĄĮy(t©»ng)╗»Ą─Ė▀┐╔ė├ĮŌøQĘĮ░ĖĪŻ
üĒ(l©ói)į┤Ż║░ó└’įŲPolarDB